Webアーキテクチャ101・簡単説明

Web開発者として始めたときに知っておいてほしい基本的なアーキテクチャの概念。
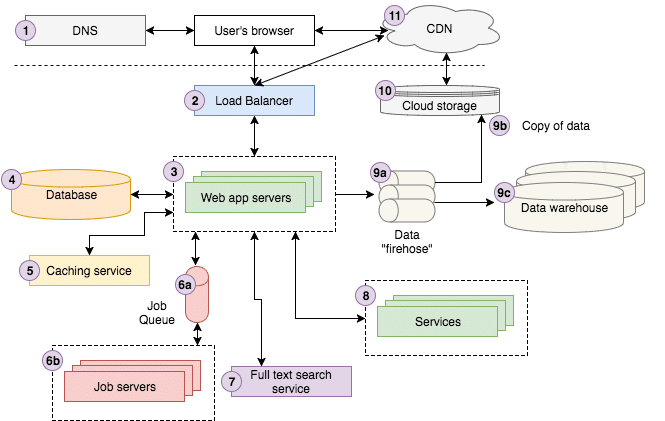
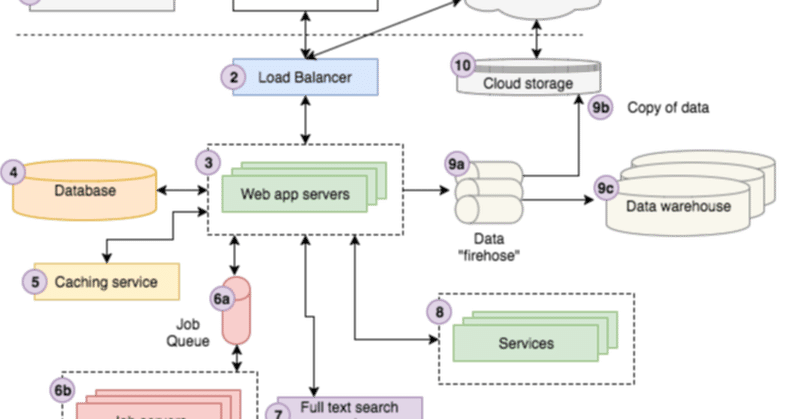
上の図は、Storyblocksでのアーキテクチャをかなりよく表しています。経験豊富なWeb開発者でない場合は、複雑になる可能性があります。各コンポーネントについて簡単に説明します。
1. DNS
DNSは「Domain Name System」の略で、ワールドワイドウェブを可能にするバックボーンテクノロジーです。最も基本的なレベルでは、DNSは、ドメイン名(google.comなど)からIPアドレス(85.129.83.120など)へのキー/値ペアの検索機能を提供します。これは、コンピューターがリクエストを適切な場所にルーティングするために必要です。電話番号と同様に、ドメイン名とIPアドレスの違いは、「JohnDoeに電話する」と「201-867–5309に電話する」の違いです。ジョンの番号を調べるために電話帳が必要だったのと同じように、ドメインのIPアドレスを調べるためにDNSが必要です。したがって、DNSはインターネットの電話帳と考えることができます。
ここで詳しく説明することはできますが、その内容はこの記事の範囲を超えています。
2. ロードバランサー(Load Balancer)
Load balancing(負荷分散)の詳細に入る前に、水平方向と垂直方向のアプリケーションスケーリングについて説明する必要があります。それらは何で、違いは何ですか?StackOverflowの投稿に非常に簡単に言えば、水平スケーリングとは、リソースのプールにマシンを追加してスケーリングすることを意味し、垂直スケーリングとは、既存のマシンに電力(CPU、RAMなど)を追加してスケーリングすることを意味します。
Web開発では、単純に安定性を維持するために、(ほとんど)常に水平方向にスケーリングする必要があります。「サーバーはランダムにクラッシュします」とか、「ネットワークが劣化します」とか、「データセンター全体がオフラインになることがあります」とか、複数のサーバーがあると、アプリケーションの実行を継続できます。つまり、アプリは「耐障害性」があります。次に、水平スケーリングを使用すると、アプリケーションバックエンドのさまざまな部分(Webサーバー、データベース、サービスXなど)をそれぞれ異なるサーバーで実行することにより、それらを最小限に結合できます。最後に、垂直方向に拡大できなくなった規模に到達する可能性があります。アプリのすべての計算を実行するのに十分な大きさのコンピューターは世界にありません。これははるかに小規模な企業に当てはまりますが、Googleの検索プラットフォームを典型的な例と考えてください。
では、ロードバランサーに戻りましょう。これらは、水平方向のスケーリングを可能にする魔法のソースです。これらは、通常は相互のクローン/ミラーイメージである多くのアプリケーションサーバーの1つに着信要求をルーティングし、アプリサーバーからの応答をクライアントに送り返します。それらのいずれかが同じ方法でリクエストを処理する必要があるため、サーバーのセット全体にリクエストを分散するだけで、過負荷にならないようにすることができます。
概念的には、ロードバランサーはかなり単純です。詳しくには確かに複雑な問題がありますが、101バージョンに飛び込む必要はありません。
3. Webアプリケーションサーバー
高レベルでは、Webアプリケーションサーバーの記述は比較的簡単です。これらは、ユーザーのリクエストを処理し、HTMLをユーザーのブラウザに送り返すコアビジネスロジックを実行します。Webサーバーは通常、データベース、キャッシングレイヤー、ジョブキュー、検索サービス、その他のマイクロサービス、データ/ロギングキューなど、さまざまなバックエンドインフラストラクチャと通信します。上記のように、ユーザーのリクエストを処理するために、ロードバランサーに少なくとも2つ、多くの場合はそれ以上を接続します。
アプリサーバーの実装では、特定の言語(Node.js、Ruby、PHP、Scala、Java、C#.NETなど)とその言語のWeb MVCフレームワーク(Express for Node.js、Ruby on Railsなど、Play for Scala、Laravel for PHPなど)を選択する必要があることを知っておく必要があります。 ただし、これらの言語とフレームワークの詳細については、この記事の範囲を超えています。
4. データベースサーバー
最新のWebアプリケーションは1つ以上のデータベースを利用して情報を格納します。データベースは、データ構造の定義、新しいデータの挿入、既存のデータの検索、既存のデータの更新または削除、データ全体での計算の実行などの方法を提供します。ほとんどの場合、Webアプリサーバーは、1つジョブサーバーと直接通信します。さらに、各バックエンドサービスには、アプリケーションの他の部分から分離された独自のデータベースがある場合があります。
各アーキテクチャコンポーネントの特定のテクノロジについて深く掘り下げることは避けていますが、データベースの次のレベルであるSQLとNoSQL。
SQLは「Structured Query Language」の略で、1970年代に発明され、幅広いユーザーがアクセスできるリレーショナルデータセットをクエリする標準的な方法を提供します。 SQLデータベースは、共通のID(通常は整数)を介してリンクされたテーブルにデータを格納します。ユーザーの過去の住所情報を保存する簡単な例を見てみましょう。 userとuser_addressesの2つのテーブルがあり、ユーザーのIDでリンクされている場合があります。単純なバージョンについては、以下の画像を参照してください。 user_addressesのuser_id列は、usersテーブルのid列への「外部キー」であるため、テーブルはリンクされています。
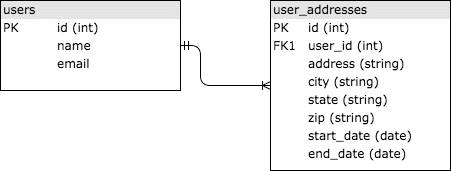
SQLについてあまり詳しくない場合は、ここのKhan Academyにあるようなチュートリアルを実行することを強くお勧めします。これはWeb開発に遍在しているため、アプリケーションを適切に設計するためには、少なくとも基本を知っておく必要があります。
「Non-SQL」の略であるNoSQLは、大規模なWebアプリケーションで生成される可能性のある大量のデータを処理するために登場した新しいデータベーステクノロジーのセットです(SQLのほとんどのバリアントは水平方向に十分に拡張できません。特定のポイントまで垂直方向にのみ拡大できます)。NoSQLについて何も知らない場合は、次のような高レベルの紹介から始めることをお勧めします。
7 Steps Understanding NoSQL
また、概して、業界はNoSQLデータベースのインターフェイスとしてSQLを使用しているため、SQLを知らない場合は、SQLを学ぶ必要があることも覚えておいてください。最近はそれを回避する方法はほとんどありません。
5. キャッシングサービス
キャッシングサービスは、O(1)時間近くで情報を検索できるようにする、単純なキー/値データストアを提供します。アプリケーションは通常、キャッシュサービスを利用して、コストのかかる計算の結果を保存します。これにより、次に必要になったときに結果を再計算する代わりに、キャッシュから結果を取得できます。アプリケーションは、データベースクエリ、外部サービスへの呼び出し、特定のURLのHTMLなどの結果をキャッシュする場合があります。実際のアプリケーションの例:
Googleは、「犬」や「テイラースウィフト」などの一般的な検索クエリの検索結果を、毎回再計算するのではなくキャッシュします。
Facebookは、投稿データや友達など、ログイン時に表示されるデータの多くをキャッシュします。Facebookのキャッシュ技術に関する詳細な記事はこちらをご覧ください。
Scaling memcache at Facebook
6. ジョブキューとサーバー
ほとんどのWebアプリケーションは、ユーザーの要求への応答に直接関連付けられていないバックグラウンドで非同期的にいくつかの作業を行う必要があります。たとえば、Googleは検索結果を返すために、インターネット全体をクロールしてインデックスを作成する必要があります。検索するたびにこれを行うわけではありません。代わりに、Webを非同期的にクロールし、途中で検索インデックスを更新します。
非同期作業を可能にするさまざまなアーキテクチャがありますが、最も普及しているのは、私が「ジョブキュー」アーキテクチャと呼ぶものです。「ジョブキュー」の2つのコンポーネントで構成されるのは、実行する必要のある「ジョブ」のキューと、キュー内のジョブを実行する1つ以上のジョブサーバー(「ワーカー」と呼ばれる)です。
ジョブキューには、非同期で実行する必要のあるジョブのリストが格納されます。最も単純なのは先入れ先出し(FIFO)キューですが、ほとんどのアプリケーションは、ある種の優先キューイングシステムを必要とすることになります。アプリは、ある種の定期的なスケジュールで、またはユーザーアクションによって決定されたように、ジョブを実行する必要があるときはいつでも、適切なジョブをキューに追加するだけです。
ジョブサーバーはジョブを処理します。ジョブキューをスキャンして、実行する作業があるかどうかを判断し、ある場合は、ジョブをキューからポップして実行します。
7. 全文検索サービス
多くのWebアプリは、ユーザーがテキスト入力して、アプリが最も「関連性の高い」結果を返すという検索機能をサポートしています。この機能を強化するテクノロジーは、通常、「全文検索」と呼ばれ、転置インデックスを利用して、クエリキーワードを含むドキュメントをすばやく検索します。

特定のキーワードからそのキーワードがタイトルに含まれるドキュメントへの高速ルックアップ(Lookup)を容易にするために、3つのドキュメントタイトルが転置インデックスに変換される方法を示す例。 「in」、「the」、「with」などの一般的な単語(ストップワードと呼ばれる)は、通常、転置インデックスに含まれないことに注意してください。
一部のデータベースから直接全文検索を実行することは可能ですが(たとえば、MySQLは全文検索をサポートしています)、転置インデックスを計算して保存し、クエリインターフェイスを提供する別の「検索サービス」を実行するのが一般的です。 SphinxやApacheSolrなどの他のオプションもありますが、今日最も人気のある全文検索プラットフォームはElasticsearchです。
8. サービス
アプリが特定の規模に達すると、個別のアプリケーションとして実行するために切り分けられた特定の「サービス」が存在する可能性があります。外界にさらされていませんが、アプリや他のサービスと相互作用します。たとえば、Storyblocksアプリには、いくつかの運用サービスと計画サービスがあります。
・アカウントサービスは、すべてのサイトのユーザーデータを保存します。これにより、クロスセルの機会を簡単に提供し、より統一されたユーザーエクスペリエンスを作成できます。
・コンテンツサービスは、すべてのビデオ、オーディオ、および画像コンテンツのメタデータを保存します。また、コンテンツをダウンロードしてダウンロード履歴を表示するためのインターフェイスも提供します。
・決済サービスは、顧客のクレジットカードに請求するためのインターフェースを提供します。
・HTML→PDFサービスは、HTMLを受け入れ、対応するPDFドキュメントを返すシンプルなインターフェイスを提供します。
9. データ
今日、企業はデータをどれだけうまく活用しているかに基づいて生きたり死んだりしています。最近のほとんどすべてのアプリは、特定の規模に達すると、データパイプラインを活用して、データを収集、保存、分析できるようにします。一般的なパイプラインには、次の3つの主要な段階があります。
1. アプリは、データ(通常はユーザーの操作に関するイベント)をデータ「firehose」に送信します。データ「firehose」は、データを取り込んで処理するためのストリーミングインターフェイスを提供します。多くの場合、生データは変換または拡張され、別の消防ホースに渡されます。 AWS KinesisとKafkaは、この目的で最も一般的な2つのテクノロジーです。
2. 生データと最終的な変換/拡張データがクラウドストレージに保存されます。 AWS Kinesisは、生データをクラウドストレージ(S3)に保存することを非常に簡単に構成できる「firehose」と呼ばれる設定を提供します。
3. 変換/拡張されたデータは、分析のためにデータウェアハウスにロードされることがよくあります。スタートアップの世界の大部分が成長しているように、AWS Redshiftを使用していますが、大企業はOracleやその他の独自のウェアハウステクノロジーを使用することがよくあります。データセットが大きい場合、分析にはHadoopのようなNoSQLMapReduceテクノロジーが必要になる場合があります。
アーキテクチャ図に示されていないもう1つのステップは、アプリとサービスの運用データベースからデータウェアハウスにデータを読み込むことです。
10. クラウドストレージ
AWSによると、「クラウドストレージは、インターネットを介してデータを保存、アクセス、共有するためのシンプルでスケーラブルな方法です」。これを使用して、ローカルファイルシステムに保存するものを多かれ少なかれ保存してアクセスでき、HTTPを介したRESTfulAPIを介して対話できるという利点があります。
11. CDN
CDNは「コンテンツ配信ネットワーク」(Content Delivery Network)の略で、このテクノロジーは、静的HTML、CSS、Javascript、画像などのアセットを、単一のオリジンサーバーから提供するよりもはるかに高速にWeb経由で提供する方法を提供します。これは、世界中の多くの「エッジ」(縁)サーバーにコンテンツを配布することで機能し、ユーザーがオリジンサーバーではなく「エッジ」サーバーからアセットをダウンロードすることになります。たとえば、次の画像では、スペインのユーザーがニューヨークのオリジンサーバーを備えたサイトからウェブページをリクエストしていますが、ページの静的アセットはイギリスのCDN「エッジ」サーバーから読み込まれるため、大西洋を横断する低速のHTTPが多く発生しません。
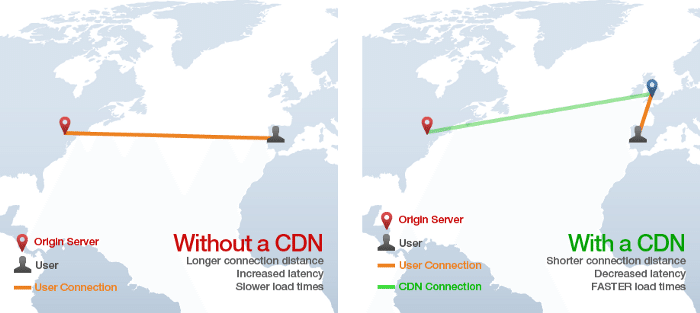
より完全な紹介については、この記事をチェックしてください。一般に、Webアプリは、CSS、Javascript、画像、ビデオ、およびその他のアセットを提供するために、常にCDNを使用する必要があります。一部のアプリは、CDNを利用して静的HTMLページを提供できる場合もあります。
これでWebアーキテクチャのまとめです。これがお役に立てば幸いです。願わくば、これらのコンポーネントのいくつかを深く掘り下げた一連の記事を投稿したいと思います。
この記事が気に入ったらサポートをしてみませんか?