手書き文字データ(ETL)を使って「ひらがな」を機械学習させてみた

はじめに
なぜ機械学習を学ぼうと思ったのか。
きっかけは「プログラミングを勉強して何か作れるようになりたい」という漠然とした想いからでした。
やるならAIなどで今流行している言語pythonかつ、機械学習を学習したいと思い、3ヶ月学習した成果をこちらに記載したいと思います。
本記事の概要
学習のまとめとして今回作成したのは【ETLを使った「ひらがな」の機械学習】です。
その作成過程を以下に記載したいと思います。
実行環境
・Windows 10
・Visual Studio 2022
・python 3.9.7
作成したプログラムの過程
ソースコードは https://github.com/Dera41397/ETL_APP です。
1.手書き文字データ(ETL)をバイナリファイルから画像に変換
ETL文字データベース
http://etlcdb.db.aist.go.jp/?lang=ja
※氏名、使用目的等を記載して登録するとダウンロード可能です。
ダウンロードしてもバイナリデータなのでそのままでは使えません。
機械学習に使えるように画像に変換します。
参考文献:
https://qiita.com/kcrt/items/a7f0582a91d6599d164d
https://qiita.com/Cyber_Hacnosuke/items/c121cfd1945a3174bc84
2.機械学習
画像に変換したデータを使用して実際に学習させます。
この学習では、畳み込みニューラルネットワーク(CNN)を用いた画像認識を行っています。
#モデル構築
model = Sequential()
model.add(Flatten())
model.add(Dense(512))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(out_size))
model.add(Activation('softmax'))KerasのSequentialモデルを定義して大量の「ひらがな」画像を学習させることで「ひらがな」を認識させます。
エポック50回学習して正解率71%となりました。

3.評価制度の推移
評価指標は、正解率 (Accuracy)と、Log Lossを用いています。
model.compile(
loss='categorical_crossentropy',
optimizer= RMSprop(),
metrics=['accuracy'])
hist = model.fit(
x_train, y_train,
batch_size=64, epochs=50,verbose=1,
validation_data=(x_test, y_test))
score = model.evaluate(x_test, y_test, verbose=1)
print("正解率 ", score[1], "loss ", score[0])
plt.plot(hist.history['accuracy'])
plt.plot(hist.history['val_accuracy'])
plt.title('Accuracy')
plt.legend(['train', 'test'], loc = 'upper left')
plt.show()
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title('Loss')
plt.legend(['train', 'test'], loc = 'upper left')
plt.show()横軸をエポックとしたtrain,testそれぞれの精度の推移はこちらです。
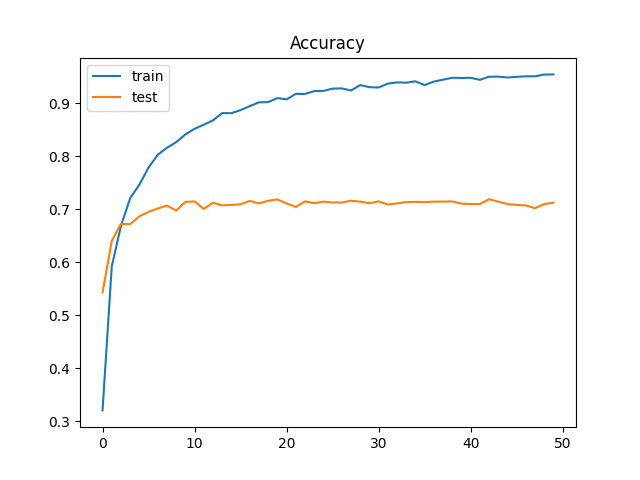
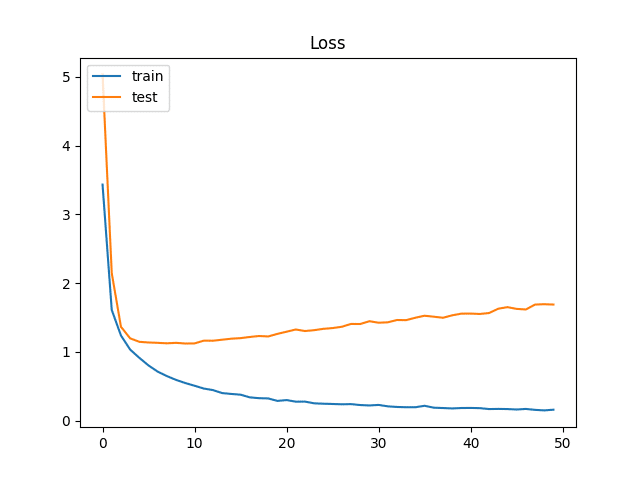
さらに正解率を85%くらい上げたいところでしたが、70回、100回と学習しても中々上がりませんでした。
画像の水増しや、転移学習、またはFineTuningを試すとより正解率が上がるのかもしれません。
おわりに
今回は用意されているデータ(ETL)を使用して学習させてみました。
もっと正解率をあげられるように画像の水増しや、転移学習、またはFineTuningにチャレンジしてブラッシュアップしていきたいと思います。
この記事が気に入ったらサポートをしてみませんか?