
【AI画像生成】絵の情報量を上げよう!

やあ、今日もミルク味のプロテインを飲んで画像生成をしているかい!?
今日は画像の"情報量"を上げる方法について語るよ!
現在、画像生成で描き込み量を増やす方法は私が知ってる内で言うと全部で5つあります。(多分もっとある、知ってたらコメントください)
描き込み量の多いモデルを使って、大きいサイズで生成する
追加ネットワークのLoRAを利用して生成する
拡張機能ControlNetのTile機能を利用する
ADetailerで顔だけアプスケしてみる
拡張機能loopback_scaler機能を利用する
これから解説する事はこれが全てなので、画像生成上級者でどんな情報も全て網羅してる自信ニキには目新しい情報皆無です。ゴメンネ。
ちな他にもSDアップスケールとかもありますが、自分の貧弱環境だと処理時間がめっちゃ長いのと、前の加筆修正記事でちょっと語ったので省いてます。ゴメンネ!
1.描き込み量の多いモデルを使って、大きいサイズで生成する
結局、これが一番の正義です。でもつよつよグラボ持ってるからって神絵が簡単に出来る分けじゃないんだよね~~。
現在流行っているモデルは詳細な結果が得られやすいものや、アニメ調のキャラクターと写実的な背景が両立するようにマージされたものが多い印象です。君だけの最強のモデルを探し出そう!
BreakDomain
※作者のBDさん曰く『背景や細部の緻密な描写にこだわってマージした』とのこと。めっちゃ最高のモデルの一つ。好き。
Pastel-Mix
※現在は生成界隈では下火ですが、イラストらしさの強いモデルとして分かりやすい情報量の多さで言えばやはりコレ
Shungiku-Mix
※Vすき焼きさん作の高精細なイラスト調のモデル
今回のサンプル画像の一部にもこちらのモデルを使用しています!
いつもありがとうございます!
これらの高精細の結果が出やすいモデルで、大きい画像を生成しようね!

解像度の差を分かりやすくした絵です。👈の絵は512×640で生成したものをExtras(その他)タブから単純に2倍サイズに拡大しました。
一方👉の絵はHires.fixを使用して2倍サイズにアップスケールしています。
ちなみに電々さんの4GBクソグラボでは512×640をx2でアプスケすると約8分かかります。……グラボ弱者は辛いぜ😢
上記の絵はcolabで生成したものですが、colabくんのようなクラウドコンピューティングサービスがなかったら低画質の絵しか作れねェんだわ……。つまり、つよつよグラボはそれだけで描き込み量の差を生むためのアドバンテージを持ってます。
さあ、夏のボーナスをグラボに注ぐんだ!!!君はそれで救われる!!
2.追加ネットワークのLoRAを利用して生成する
とまあ、冗談は置いておいて神グラボを持つこと以外にも色々と方法はあります。最近流行っている手法は追加ネットワークである『LoRA』を用いる方法です。
特に、フラットな塗り系LoRAを『マイナス指定で適応する』と全体の構図を損なわないまま描き込み量だけ増やす事が出来る!という手法が一時期話題を呼びました。この画期的な手法は画像生成界隈ではほぼ定着したと言っていいと思います。
一方で、そのまま正の方向を指定する事で描き込み量を増やすLoRAも発表されているので、自分が知っているものを4つご紹介いたします。
その7「flat」
— 2vXpSwA7 (@2vXpSwA7) May 12, 2023
適用すると絵がフラットな感じになります
そしてマイナス適用で描きこみが増える増える
これも2つありますが、彩度や明度への影響が違います、出したい絵に合わせて使い分けてください pic.twitter.com/wlFsgaUoQv
LoRA使用時の全体的なデメリット
構図が大きく変化する場合がある
一応ある程度緩和する方法として、拡張機能のComposable Loraを使用するかLoRA Block Weightで構図周りのみを切って出力させるなどあります。
Composable Loraは web ui アップデートすると使えなくなる場合があります。1.3.1環境だと他の方がフォークしたverがあるのでそれを試してみるといいかも。(https://github.com/NuriDerBurrito/SD-composable-lora とか https://github.com/a2569875/stable-diffusion-webui-composable-lora)
LoRA Block Weightは自分用の構図周り切ったプリセット置いておきますね→KOUZU:1,1,1,0,0,0,0,0,0,0,0,1,1,1,1,1,1
今回比較に使うイラスト
※環境により同じ絵が出ない場合があります。サンプル出してますがあくまで簡単な参考例程度に見てください。

flat2

上の方で貼ったツイート主である2vXpSwA7さんが作られたLoRAです
全体的に構図への影響が少ない気がします(体感)
ただ配布ページ上でのサンプル画像ではかなり構図変わってる気がするので、環境の差もあるかもです。
今回イチオシはこれ!みんな使ってるしネ
Minimalist Anime Style

構図変化度がめちゃくちゃ高い!
背景にもめっちゃ影響出る
flatは色味が若干濃くなりすぎるが、こっちは割りと明るく出る?
使いこなせれば良いのが出来そうな予感はする
手指の破綻も増えそうな予感がする
Add More Details

注意点として、これは正の方向に重みかけて使います
リアル・実写系モデルにも使用できます
構図変化力が大きそう?自分の出した絵だと0.5くらいはそこまで目立たなかった
背景を大きく変化させる効果も多分ある?
白い部分がぼやっとしがちかも知れない
Detail Tweaker LoRA

これも正の方向に重みかけて使います
0.5くらいなら構図も大きくは変化しない(上の画像だとなぜか水没してるけど……他の例だとそこまで大きくなかった)
Add More Detailsと比べると彩度が抑えめになってるので、ギラギラした感じになりづらい印象がある
手指の破綻もminimalistとかaddmoreと比べて少な目かも?
3.拡張機能ControlNetのTile機能を利用する
これも一時期界隈で話題になっていた手法です。ControlNetの新機能Tileは元画像のイメージを保ったままアップスケールが出来る機能のこと。
「それHires. fixと何がちゃうねん?」て言うと、TileはControlNetの一部なので画像の一貫性を保ちながら細部の描き込みを増やす効果が期待できるってこと。

Hires.fixは要はi2iのようなもので、ノイズ除去強度に応じて絵が変化します。以下は特に元絵と変わってしまった箇所を、分かりやすいように〇つけしたものです。

ここらへんを、元絵からの変更を極端に抑えた状態でアップスケール出来るのがControlNet Tileの利点です。
さらにControlNet Tileは項目を弄れるので、どのstep数まで適応するかとかを設定できたり、出力後の絵を何度も何度もControlNetにかける事でHires一発では無理なほどエグい描き込み量を追加する効果も期待できます。

1回目の画像をControlNetに入れたのが2回目、2回目のを入れたのが3回目です
こんな感じで、胸元の花柄模様とか追加されてるのがよく分かりますね。下段だと服の皺影が徐々に増えて行く様子とか、胸元の宝石とかもディティール上がっていってます。
色も大分変化しちゃってますので、何かとのトレードオフな感じもしますね。設定を見て行きましょう。
設定画面(下段の方で使ったやつ)

効果が強く出すぎる時や、繰り返し処理をする時はEnding Control Stepも数値を落とすといい。
プリプロセッサの違い
tile_resample→最初から選ばれてるやつ、上の参考図みたいに色が変わってしまうのであんまオススメしない
tile_colorfix→resampleの色が変わる問題を修正したやつ
tile_colorfix+sharp→colorfixからさらに線がシャープになるように修正されたやつ。参考図の下の方がこれ。基本的にはコレを使えば問題ない。
Hires.fixと両立して使うのが多分モアベター

処理としてはTile処理が終わった後にアプスケ処理が入るっぽい
全体の一貫性は保ちつつ、hiresでよりいい感じになる。ただしhiresの効果で一貫性はやっぱりくずれる。手指が破綻してたり、飾りの色が変わったなど、一長一短。
あとはmultidiffusion-upscalerと組み合わせて、より全体を高画質化していく方法も見かける。
設定画面


髪の描き込み量が増えてシャープでパキっとした絵になったゾイ
※注意点 Tile使用時はアップスケールも並行した方が効果が得られやすい。
512x512アプスケなしで出した絵をControlNetに入れて生成する時は、hires使うか、hires使用しない場合は生成サイズそのものを1024×1024とかに変えてから生成すると多分上手くいきやすい。
4.ADetailerで顔だけアプスケしてみる
これは過去の加筆修正関連の記事で再三言ってる事ですが、人が一番注目するのは人の顔です。
群れを作る生き物として最適化してきた人類は、他人に対して敏感です。これは表情の変化から感情を読み取り、相手が仲間かどうかを判別するためじゃないかなっていう。(素人考え)
なので最悪言うと『顔さえ高品質なら他は適当でもいい』とも言えます。何せ顔は一番目立つ箇所なので。
他にも、情報量に差を作った方が視線誘導の観点からもいいので、顔だけを認識してアップスケールしてくれる拡張機能ADetailerはめちゃくちゃ強力です。
これがなかった頃は、顔だけ切り出して拡大してからインペイント→出来た画像を縮小して顔部分に貼り付けるみたいな手間のかかる事やってました。楽になったもんだぜ!


設定画面

顔認識画像(赤い枠のやつ)を別途保存したい時は、設定画面からチェックを入れようね。
5.拡張機能loopback_scaler機能を利用する

今回の本命です。以前からi2iを繰り替えす事で出来が良くなるよねっていうのが時折言われてました。
それを画像を徐々にアップスケールしながら自動でやってくれる&ラストに画像の補正もしてくれるのがこの拡張機能です。
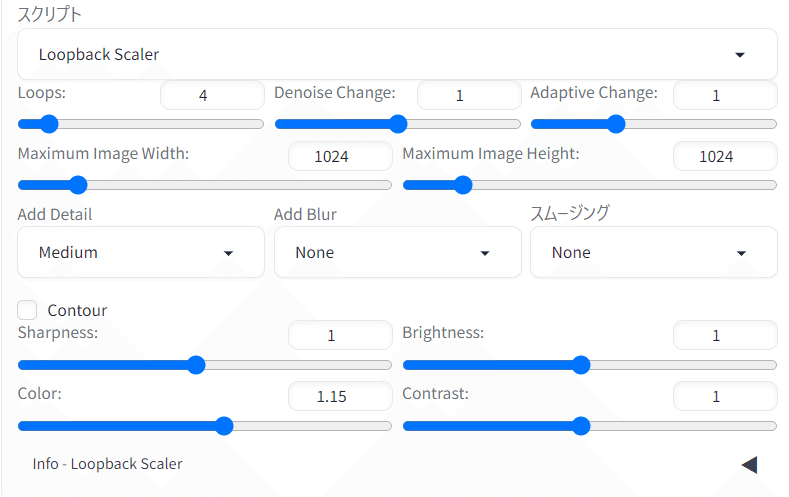
設定画面

使い方

まず、なんかいい感じの画像を生成します。hiresはしてもしなくてもいいですが、自分はグラボが貧弱なので大きな効果を得るためにhires前の画像から始めています。

一応仕組みとしてこのようになっています。元絵からMaximum Image WidthとHeightのサイズまでアップスケールをしますが、それをLoopsで設定された回数分徐々にサイズアップするように自動で数値を割り振って繰り返してくれるって感じ。
注意点と対処
VAEを使っているとなぜかめっちゃ色がくすむ
対処法1. ループ数を通常よりも少なくする
対処法2. Colorで彩度上げたり、Brightnessで明るさ上げて対処する
対処法3. 生成後に画像編集ソフトで直す
対処法4. そもそもVAE埋め込み済みのモデルを使う
対処法5. 生成後にVAE埋め込んだモデルでもう一回i2iする
当たり前だがサンプラーの影響を大きく受ける
作者オススメの設定は次の通り(設定例の画像はこれに沿っているので、あれをそのまま真似する感じでOK)
Resize mode: Crop and resize
Sampling method: DDIM
Sampling steps: 30
Width/Height: 340x512 or 512x768. 元の画像のアスペクト比を維持するように努めますが、元の画像の解像度よりも低く設定することもできます。
CFG Scale: 6 to 8
Denoising strength:0.2~0.4が普通です。低くするほど、ループ間の変化は少なくなります。レベルを上げるほど、最終結果は元の画像と似なくなります。
Seed: これはあまり問題ではありません。通常は -1 のままにします

と言う訳で比較がコレです。Hiresよりも明らかに描き込み量が全体で増えましたね!i2iを行う都合上、服装などの細部は大分変わってしまいましたが、もしかしてControlNetとかと組み合わせるといいのかも?
つよつよグラボ持ってる人は出来るかもね!!
色がめっちゃくすんでるんだが????
作者本人が言ってる通り、VAEを使うと画像がフェードアウト?するらしいです。まあくすむってコトですね。注意点にも対処法載せましたが、ループ数を通常よりも少なくする・彩度とか上げる機能もついてるのでそこで調整するとかで対処できます。
自分はSungikuMixを使っていたので、一端VAEを抜いてサンプラーはDDIMからDPM++ 2M SDE Karrasに変更してから、完成済みの絵をloopback処理をOFFの状態でもう一度i2iしました。

それで出来たのがコレですね! loopback処理、オススメです!!
終わりに
と言う訳で、文章多めで色々な方法を語りました。
役に立ったと思った方は、ぜひイイネを押してくださると嬉しいです。
続きとして、AI画像生成者向けの絵の視線誘導についての記事を公開しました。そちらもよろしくお願いいたします! 過去記事も読んでね!
この記事が気に入ったらサポートをしてみませんか?