DjangoからAmazon Transcribeを使う

Amazon TranscribeはAmazon Web Serviceの機械学習サービスの1つで、音声をテキスト情報に変換してくれるサービスです。
Amazon Pollyとは逆のことをしてくれます(*´∀`*)
音声から文字起こしをするのって結構大変ですよね。会議の録音を聴きながら議事録を作成しようとすると、会議時間×2倍ぐらいの時間がかかってしまいます。(そんな一言一句、完コピしなくていいじゃんと思いますが)
Amazon Transcribeに音声ファイルを投げるだけで、全部文字にしてくれるんだったら、すごい楽ですよね。もう音声ファイルと、Amazon Transcribeの出力だけ添付して、決定事項だけ書ければいいんじゃないかと妄想しています。
では、さっそくAmazon Transcribeを使っていきましょう!
パッケージのインストール
DjangoからAmazon Transcribeを使うには、3つのパッケージが必要になります。django、boto3、そしてawscliです。
boto3は、AWS SDK for Pythonと呼ばれるもので、要するにAWSにアクセスしたい時に使う、Python用のSDKですね(SDK:Software Development Kit)。名前の由来がよくわからないので、とても覚えにくいです(´;ω;`)
そして、awscliはAWS Command Line Interfaceの略で、AWSにコマンドラインからアクセスできるようにするツールです。
この2つを連携させることで、Amazon Transcribeを使うことができるようになります。
また、今回はAmazon S3も使うので、django-storagesもインストールします。
最後に、Amazon Transcribeからのテキスト出力結果を、ダウンロードする必要があるので、requestsというパッケージもインストールしておきます。
…というわけで、さっそくPythonの仮想環境に入って、これらのパッケージをインストールしていきます。
pip install django
pip install boto3
pip install awscli
pip install django-storages
pip install requestsインストールはこれだけで完了です!
AWSでIAMユーザーの作成
続いて、Amazon Transcribeで利用するIAMユーザーを作成します。
IAM(Identity and Access Management)は、AWSでユーザー作成やその権限などを設定できるサービスです。AWSアカウントを作成すると、ルートユーザーと呼ばれる、全ての権限をもったユーザーが作成されます。ただ、そのルートユーザーでなんでもできてしまう、というのが問題になることがあります。
ルートユーザーが乗っ取られた場合、悪意を持った人がなんでもできてしまうかもしれません。アカウントを共有していたら、誰が何を変更したのかわからない状態になります。
このような状態を避けるために、それぞれの用途に合わせてIAMユーザーを作成し、各ユーザーにそれぞれ必要な必要最低限の権限を与えることで、もしもの場合に備えておくことができます。
今回はAmazon Transcribeだけを使うので、Amazon Transcribeしか利用できないユーザーを作成するというわけですね!
まずは、AWSマネジメントコンソールでIAMサービスを選択し、左側のメニューから[ユーザー]を選択します。
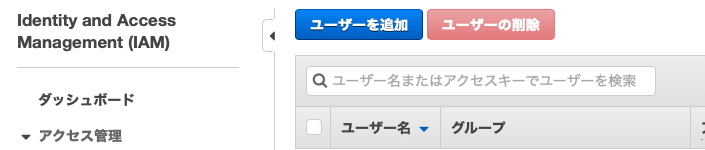
画面上部にある[ユーザーを追加]ボタンを押して、ユーザーの作成を始めていきます。
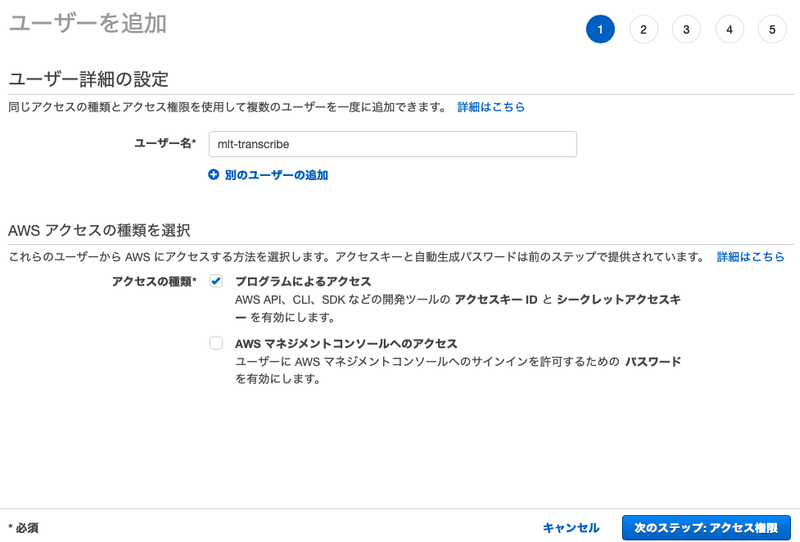
作成画面に入ったら、適当に名前をつけてユーザーを作成します。名前はなんでもいいですが、あとでどんなユーザーかわかりやすいようにしておく方が良いでしょう。
下の、[AWSアクセスの種類を選択]に関しては、今回は[AWSマネジメントコンソールへのアクセス]は必要ないので、[プログラムによるアクセス]にだけチェックを入れます。
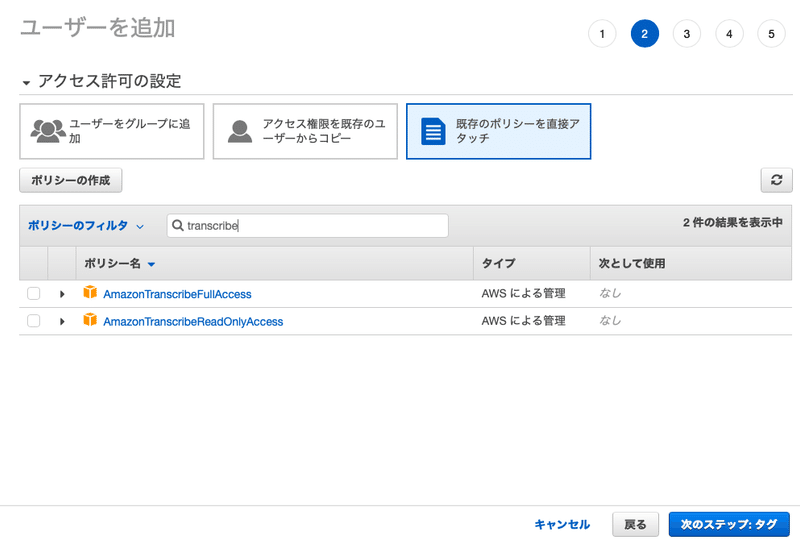
次に進むと、アクセス許可を設定する画面になります。
[ユーザーをグループに追加]は、同じような権限を持ったユーザーを複数作成するのであれば、グループを作成しておくと便利です。そのグループにユーザーを追加/削除するだけで、そのグループに設定した権限を与えたりなくしたりすることができます。
[アクセス権限を既存のユーザーからコピー]はそのままですね。
今回は新しく作るので、[既存のポリシーを直接アタッチ]を選択します。ポリシーはAWSのサービスの利用権限を細かくわけています。このポリシーの一覧の中から必要な権限を選んで、ユーザーに付与することができます。
Amazon Transcribeを使う場合は、検索バーに"transcribe"と入力して、Amazon Transcribe関連のポリシーをフィルターしましょう。
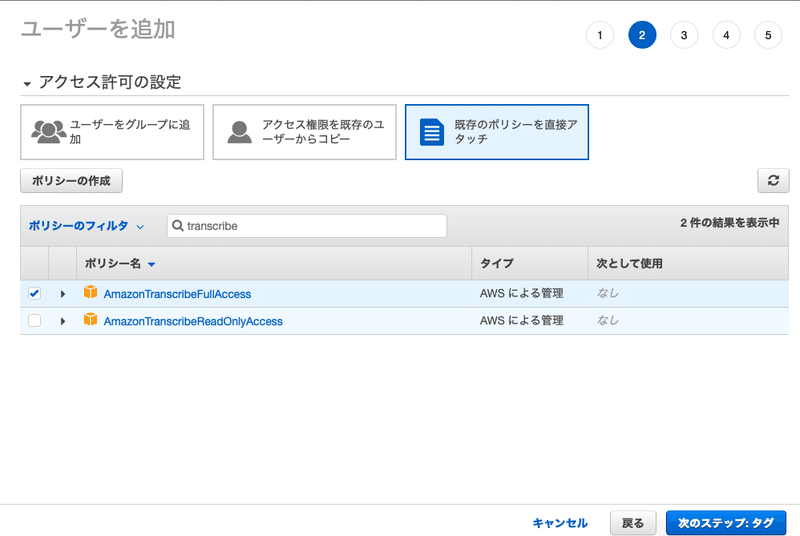
[AmazonTranscribeFullAccess]にチェックを入れます。
また、今回はS3へのアクセスも必要なので、"S3"を検索バーに入力し、[AmazonS3ReadOnlyAccess]も追加しておきます。
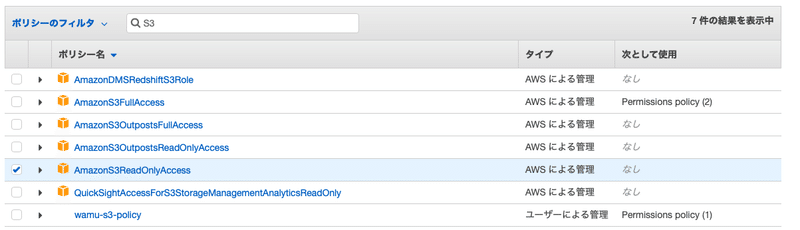
Amazon TranscribeからS3への書き込みは必要ないので、ReadOnlyにしています。
タグの追加は任意です。作成しているサービスごとにタグを作っておくと、一覧にしたい時に便利です。
最後に確認画面があります。
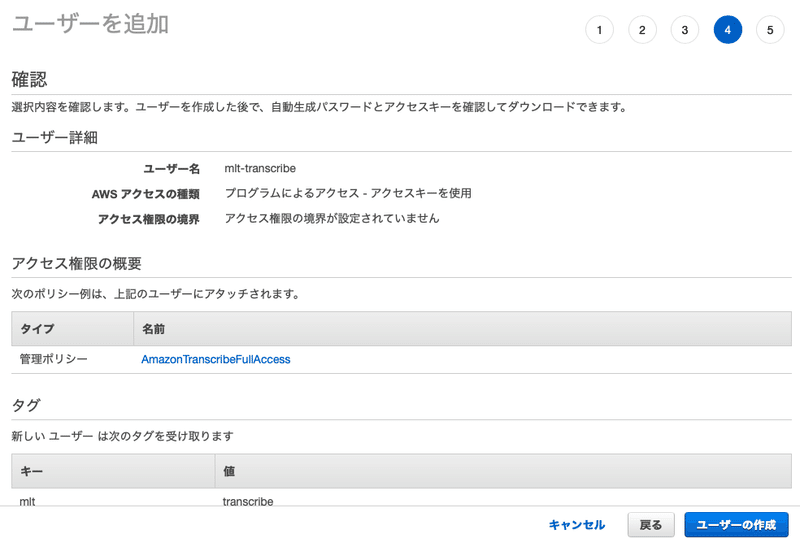
確認して問題なければ、下の方にある「ユーザーの作成」ボタンを押します。

成功すると、サインイン用のアドレスや、アクセスキーID、シークレットアクセスキーをダウンロードできる画面になります。(画像ではセキュリティのため表示しません)
これらのキーを記憶するのは困難なので、忘れずに.csvファイルをダウンロードしておきましょう。このファイルは厳重管理しておきます。
AWS CLIのインストール
boto3からAWSサービスにアクセスするためには、利用するIAMユーザーを設定しなければなりません。そのための事前設定として、awscliに先ほど作成したキーを登録する必要があります。
awscliインストール後に、以下のコマンドを入力するとセットアップが開始されます。
aws configureすると、先ほどIAMユーザーで作成したアクセスキーIDなどを求められますので、それぞれ入力していきます。
今回、S3を使うので、S3のバケットがあるリージョンと同じリージョンに設定しておきましょう。僕の場合は、東京リージョンなので"ap-northeast-1"に設定しました。
出力フォーマットはjsonにします。
Default region name [us-west-2]:ap-northeast-1
Default output format [None]:json※一応利用しているリージョンでAmazon Transcribeが利用できるかは確認してくださいね。
これでAWS側の準備は完了です。
あとは、DjangoでAmazon Transcribeを使ったモデルを作っていきましょう。
※プロファイルの複数追加について
もし、Amazon Pollyなどで、他のIAMユーザーを同時に利用するのであれば、以下のコマンドで新しいプロファイルを追加してください。"--profile"がない場合は、defaultという名前のプロファイルで設定されます。
aws configure --profile transcribe_prof最後の要素はプロファイルの名前なので、自由に設定できます。後でAWSに接続する際に使うので、覚えておいてください。
ちなみにプロファイルの一覧は以下のコマンドで確認できます。(linux系の場合)
vi ~/.aws/credentialsDjangoのtranscribeアプリケーションの作成
これからtranscribeというアプリケーションを作成していきますが、大部分は以前に書いたこちらの記事と一緒なので、違うところだけ紹介していきます。
今回は、以下コマンドでtranscribeアプリケーションを作成し、このアプリケーションにCRUDのCreateとRead部分を実装していきます。
python manage.py startapp transcribetranscribeアプリケーションのモデル
今回はシンプルに作りたいので、モデルにも最低限の情報だけつけていきます。(本当はモデルも作る必要はありませんが、このほうがわかりやすいと思うので…)
# transcribe/models.py
from django.db import models
import uuid
import os
def rename_audio(instance, filename):
ext = filename.split('.')[-1]
filename = '{}.{}'.format(str(instance.id), ext)
return os.path.join('transcribe_audio', filename)
class Transcribe(models.Model):
id = models.UUIDField(primary_key=True, default=uuid.uuid4, editable=False)
audio = models.FileField(upload_to=rename_audio, blank=True, null=True)
text = models.TextField(max_length=400)まずidにUUIDを設定します。これはアップロードする音声ファイル名にUUIDを設定して被らないようにするためです。実際のファイル名の変更はrename_audio関数で実施します。この関数の詳細は以下の記事で解説しています。
audioは、音声ファイルをアップロードするフィールドです。
textは、音声ファイルを文字起こししたテキストを格納するフィールドになります。
さて、Amazon Pollyでは、MEDIA_URLとMEDIA_ROOTを設定しましたが、Amazon TranscribeではAmazon S3を利用する必要があります。
その理由は、音声ファイルをs3://やhttp(s)://のアドレスで渡さないといけないからです。そのため、ローカル環境に保存しているファイルだとAmazon Transcribeに渡すことができません。
Amazon S3の細かい設定方法は以下の記事を参考にしてください。
ざっくり概要
# S3のバケットを用意
バケット名:skilla-daikinishimatsu
# settings.pyに以下を追加
DEFAULT_FILE_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage'
AWS_STORAGE_BUCKET_NAME = 'skilla-daikinishimatsu'
AWS_S3_REGION_NAME = 'ap-northeast-1'
AWS_ACCESS_KEY_ID = os.environ.get('AWS_ACCESS_KEY_ID')
AWS_SECRET_ACCESS_KEY = os.environ.get('AWS_SECRET_ACCESS_KEY')
# 環境変数の設定を忘れずに。
export AWS_ACCESS_KEY_ID="あなたのアクセスキーID"
export AWS_SECRET_ACCESS_KEY="あなたのシークレットアクセスキー"transcribeアプリケーションのCreateView
さて、ちょっと手間がふえて大変でしたね。ようやくtranscribeアプリケーションの作成に入れます。
処理の流れとしては、フォームに音声ファイルを登録し、その音声ファイルをAmazon Transcribeに渡して、テキスト情報を作成してもらいます。Amazon Pollyと似たような感じですが、異なる部分もありますので、注意しながら進めてください。
まずは、フォームに入力した後に、Djangoが[form_valid]関数を呼ぶので、それを使います。
[form_valid]はフォームに入力された内容に問題がなかった場合に、呼ばれる関数です。ここでaudioに登録されたurlをAmazon Transcribeに渡して、テキスト情報に変換してもらうことにします。
まずはTranscribeCreateViewがどうなっているかみてみましょう。
# transcribe/views.py
from django.views import generic
from django.urls import reverse_lazy
from .models import Transcribe
class TranscribeCreateView(generic.CreateView):
model = Transcribe
template_name = 'transcribe/create.html'
success_url = reverse_lazy('transcribe:list')
fields = ['audio']
def form_valid(self, form):
transcribe = form.save(commit=True)
response = use_transcribe(transcribe.id,transcribe.audio)
try:
transcribe.text = response["results"]["transcripts"][0]["transcript"]
except:
pass
transcribe.save()
return super().form_valid(form)フォームで入力するフィールドは、audioだけなので、fieldsにはaudioだけ書きます。textはaudioから作成するフィールドなので、入力されては困ります。
[form_valid]関数では、form.save(commit=True)と呼ぶことによって、フォームで入力した内容から作成されるモデル(transcribe)を取得します。commit=Trueとしているのは、一旦S3に音声ファイルを保存してもらわないと、Amazon Transcribeの処理ができないからです。
Amazon Pollyの時と同じようにuse_transcribe関数から結果を返してもらって、その中に情報があれば、textフィールドに保存しています。この関数については、後述します。
これでモデルのデータが完成しましたので、最後にtranscribe.save()でデータベースに保存して完了です。
Amazon Transcribeへのアクセス方法
最後にuse_transcribe関数の中身を紹介しておきます。最低限の実装として以下のようにしました。
# transcribe/views.py
def use_transcribe(id,audio):
# create session
session = Session(profile_name="transcribe_prof")
transcribe = session.client("transcribe")
# set job info
job_name = str(id)
job_uri = audio.url.split("?")[0]
transcribe.start_transcription_job(
TranscriptionJobName=job_name,
Media={'MediaFileUri': job_uri},
MediaFormat='mp3',
LanguageCode='ja-JP'
)
# wait until job ends
while True:
status = transcribe.get_transcription_job(TranscriptionJobName=job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(5)
try:
response = requests.get(status['TranscriptionJob']['Transcript']['TranscriptFileUri'], allow_redirects=True)
return response.json()
except:
return None最初にboto3を利用してAWSと接続するセッションを作成します。profile_name="default"と指定すると、aws configureで設定したアクセスキーIDなどでAWSに接続します。僕は"transcribe_prof"に設定したので、こちらを使います。
そして、次の行で"transcribe"を使うクライアントを作成します。job_nameはジョブの名前なのでIDを使い、job_uriには、音声ファイルの場所を設定します。
audio.urlのファイル名の後ろに余計な情報がたくさんついていて、最初うまくいかなかったので、"?"の後を消して渡しました。
これで事前準備が完了しました。
次のtranscribe.start_transcription_jobで、実際にAmazon Transcribeに接続しに行っています。設定をしている値は見ればわかる感じなので、説明は必要ないかと思います。
ここで、Amazon Pollyと違うのは、この関数から直接結果を返してくれないところです。
処理に意外と時間がかかるので、ステータスを確認して、終わったかどうか随時チェックしています。短い音声ファイルですが、15~20秒ほどかかってしまいます。
最後に、statusから結果を保存しているurlを指定し、getで実際のデータを取得しています。そのデータを扱いやすいようにjson()で変換して結果をreturnしています。
これでAmazon Transcribeを利用して、音声ファイルをテキスト情報に変換して、データベースに保存することができるようになりました。
おまけ
statusの中身の例。
# status
{'TranscriptionJob':
{'TranscriptionJobName': '186f54fa-523c-489d-9341-4ae819a0650d',
'TranscriptionJobStatus': 'COMPLETED',
'LanguageCode': 'ja-JP',
'MediaSampleRateHertz': 22050,
'MediaFormat': 'mp3',
'Media': {
'MediaFileUri': 'https://skilla-daikinishimatsu.s3.amazonaws.com/transcribe_audio/fd392708-9633-4232-a04f-b4a41caca865.mp3'},
'Transcript': {
'TranscriptFileUri': 'https://s3.ap-northeast-1.amazonaws.com/aws-transcribe-ap-northeast-1-prod/377818748129/186f54fa-523c-489d-9341-4ae819a0650d/d74f0a7e-b0ff-4c2e-8623-b4d219ebeb26/asrOutput.json?X-Amz-Security-Token=IQoJb3JpZ2luX2VjEBsaDmFwLW5vcnRoZWFzdC0xIkcwRQIgb6ZLDgIA%2F62YdFxnc%2BsJhJzxQc9gMJSfan%2FDV6PuM0oCIQDmKYztby5HXGJGGCno7PimVLIqawXPmX8%2FsH2si1i1Ayq%2BAwh0EAEaDDAxNTUzMzUyNzE5NSIMeCaXmFegz%2FdcN87EKpsDgTKKEmQPIIFJ79VUOkOCatOooKK3%2FLrBDton1QubB7ivCsQgbomvdlKtWCP3H990n0T%2B1t%2BhGp7r5iMss7kQz2cZdehKe%2FAZ7qSPJhJ%2BMVpywXXmr9zPfFVNsWUGs34VbSreYiysp7%2FMzDFKGW2GkqkkamiFetV8jMb7oV4hywVCUNFCveMQ2ZNuWZVz7DlGvdLy%2FGtybrYxkBXa0%2Fx6Rn59JuNinsE4ZZeGW5LmqA17VD%2F9Cdqw3PgyT5dmzWVTvtnpqJmZXuu%2B9Sie1Sz0ZYQgpz5B0YmAYt3kGfBTQPPy1W0%2FhogUa%2Fx%2F%2BUQ35TfjKRL7MSiL4jxR4obCw6FJgW1tyIxwtyaoHpXrR%2F1SfS8ECdvaCZTuV8llri4AcS3K2uRrt6sBQGeucUpBn%2FcKcD8cEPpu4VOmpquP45QBhHLV6V8aSgwsUh9FqTNNl5qMi54Xd%2FsnnWyQgjv5G2k7uX1AG2uMIKG91RpW%2FbkfOWc4nvqcdMR%2FnIIW3KQbem7jXWWbnL6Tp%2BOfEH4Kui85RdESO15y05ijop39MJjpwIMGOusBNP1fW0YV%2BukZjdzVubSc9vtxmNyOCql2w45fktUxqho5NZCP6MHL7AyRNeKfNndBBG1Lo44WLlKCl1REn%2Bo9Kwb7RySZGhbwJdDLtb0ZuDYTcMO9KelO%2F%2B9qxDWWcBtdi7bi%2FutH80zh0CqAzj1%2BdrfbSRR2P08%2BeA4e4%2BX5qGfR%2BGBfOYp6AcrJUa37lpKtR9u37nnFoAyiWE1%2FwrMrUcr8%2F9%2BLZS9m9Lz%2FpzE6rwKsHyeF0bZBwNbvpauD8Smr926d4KNwg%2Bd%2FA0elm1npAofNlkrxR4J6mH7DYeTR5CyuOk4PtI6O8T9D%2Bw%3D%3D&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Date=20210409T114642Z&X-Amz-SignedHeaders=host&X-Amz-Expires=899&X-Amz-Credential=ASIAQHHO62CN2TIALLRM%2F20210409%2Fap-northeast-1%2Fs3%2Faws4_request&X-Amz-Signature=870eaaaa95760252be04d1d3176028ec998c4605b02e970becbe2f6abddb577c'
},
'StartTime': datetime.datetime(2021, 4, 9, 11, 46, 21, 420000, tzinfo=tzlocal()),
'CreationTime': datetime.datetime(2021, 4, 9, 11, 46, 21, 391000, tzinfo=tzlocal()),
'CompletionTime': datetime.datetime(2021, 4, 9, 11, 46, 37, 811000, tzinfo=tzlocal()),
'Settings': {
'ChannelIdentification': False,
'ShowAlternatives': False
}
},
'ResponseMetadata': {
'RequestId': 'c77937f1-2c99-4ce8-adf6-f082cc431b33',
'HTTPStatusCode': 200,
'HTTPHeaders': {
'content-type': 'application/x-amz-json-1.1',
'date': 'Fri, 09 Apr 2021 11:46:41 GMT',
'x-amzn-requestid': 'c77937f1-2c99-4ce8-adf6-f082cc431b33',
'content-length': '2147',
'connection': 'keep-alive'
},
'RetryAttempts': 0
}
}Amazon Transcribeでの出力結果の例。
# asrOutput.json
{"jobName":"186f54fa-523c-489d-9341-4ae819a0650d",
"accountId":"377818748129",
"results":{
"transcripts":
[{"transcript":"吾輩 は 猫 で、 ある 名前 は まだ ない"}],
"items":[
{"start_time":"0.04","end_time":"0.58","alternatives":[{"confidence":"0.9493","content":"吾輩"}],"type":"pronunciation"},
{"start_time":"0.58","end_time":"0.73","alternatives":[{"confidence":"1.0","content":"は"}],"type":"pronunciation"},
{"start_time":"0.73","end_time":"1.04","alternatives":[{"confidence":"1.0","content":"猫"}],"type":"pronunciation"},
{"start_time":"1.04","end_time":"1.18","alternatives":[{"confidence":"1.0","content":"で"}],"type":"pronunciation"},
{"alternatives":[{"confidence":"0.0","content":"、"}],"type":"punctuation"},
{"start_time":"1.18","end_time":"1.44","alternatives":[{"confidence":"1.0","content":"ある"}],"type":"pronunciation"},
{"start_time":"1.81","end_time":"2.28","alternatives":[{"confidence":"1.0","content":"名前"}],"type":"pronunciation"},
{"start_time":"2.28","end_time":"2.5","alternatives":[{"confidence":"1.0","content":"は"}],"type":"pronunciation"},
{"start_time":"2.72","end_time":"3.03","alternatives":[{"confidence":"1.0","content":"まだ"}],"type":"pronunciation"},
{"start_time":"3.03","end_time":"3.31","alternatives":[{"confidence":"0.9916","content":"ない"}],"type":"pronunciation"}
]
},
"status":"COMPLETED"
}あとは、いろいろ遊んでみてください!(*´꒳`*)
サンプルサイト
repl.itにここまでに作成した内容を残しておきます。左側にあるCodeタブを選択すると、ファイル構成やファイルの内容を確認できます。
今回は、repl.itだとAmazon S3へのアクセス権がないので、実行しても詳細ページを表示できません…。
なので実行結果の画像を貼っておきます。
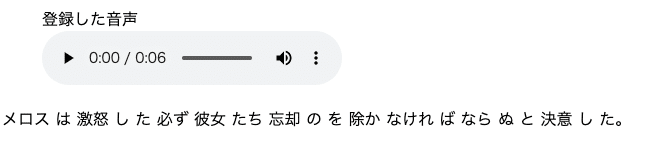

※repl.itからAmazon Transcribeに接続できないので、データの追加/変更はできません。
もし試したい方は、自分の環境にサンプルサイトをダウンロードして、awscliや環境変数にあなたのアクセスキーIDやシークレットアクセスキーを設定してください。
最後に
最初の料金は1 秒あたり 0.0004USDなので、1分で0.024USD、60分で1.44USDです。約150円ぐらいでしょうか。普通に議事録を作るよりはずっと安そうですね。
精度は…うーん、音声や内容にもよるんだろうけど、まだまだなのかな?精度を上げる設定もあるので、これだけじゃまだわかりませんが…。
今回はたぶん邪智暴虐が悪さをしているんだと思います(笑)
ここまで読んでいただけたなら、”スキ”ボタンを押していただけると励みになります!(*´ー`*)ワクワク
この記事が気に入ったらサポートをしてみませんか?