
【Pythonによるデータ分析①】Pythonでツイッターのオリジナルデータから、拡散されやすいツイートを分析してみよう!

Pythonでデータ分析をしてみたい!と思っても、なかなか面白いデータはありませんよね。そこで、今回はPythonを利用して、ツイッターのオリジナルデータを分析するチュートリアルを書いて見たいと思います。
このチュートリアルの内容
この第一弾の記事では、どういう記事がリツイートされやすいかを分析しました。そのデータ分析の流れを、データの前処理から可視化、分析までの流れを初学者でもわかりやすいように解説いたします。
・文字数が多いツイートって本当にリツイートされやすいの?
・箇条書きツイートだと、お役立ち感があってリツイートされやすいの?
こういう仮説を、データで検証していくような感じです。
また、フォロワーを増やすためには何が必要かをデータで洗い出すという記事も以前書きました。今後第二弾の記事では、この分析の流れも解説します。
このチュートリアルで学べること
このチュートリアルでは
・Twitter Analyticsからのデータの取得方法
・Microsoft Azure Jupyter Notebookを利用した、環境構築不要なPythonの実行環境の準備方法(無料)
・Pandasを利用したデータの前処理
・相関係数等の基礎的な統計の知識
について、ツイッターの実際のデータを利用しながら学ぶことができます。実際に生のデータを利用して、インサイトを見つけられるので、面白いです。ソーシャルデータの分析をしてみたい!という方は、ぜひよんでみてください。
具体的には、僕の実際のツイートのデータをダウンロードしていただき、そのデータをもとにどういうツイートが拡散されやすいのかをデータ分析してもらうというような形になります。まずはデータ数が多く、リツイート数の多い僕のデータをもとに、分析を進めます。
チュートリアルが完了したら、ぜひ自分のツイートを分析してみるのがよいでしょう。
僕のツイートのデータはこちらからダウンロードできます。まず、こちらのデータをダウンロードしたうえで、はじめてください!
このチュートリアルを学ぶ前に
このチュートリアルを学ぶ前に、以下のコースを学習しておいてください。
・ProgateのPython1-5 ※必須
・AidemyのPandas ※勉強していると学習が楽です!
Twitter Analyticsで直近のデータの取得
それでは、まず最初に自分のツイッターのデータを取得してみましょう。Twitter Analyticsを開き、過去5ヶ月分のツイッターのデータを取得してみましょう。使い方についてはこちらのデータを見てください。
まず、自分のツイッターにログインして、ツイッターアナリティクスを選択します。
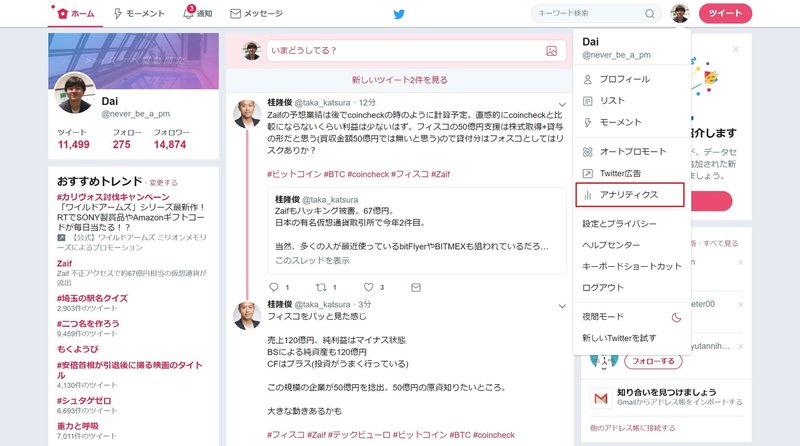
次に、データを取得したい期間を選択し、データをエクスポートを選択します。期間は1カ月単位でしか選択できなかったはずなので、複数月とりたい場合は、何度か区切って取得してください。今回僕が取得したデータは、4月から8月までのデータで分析を行ったので、april.csv ~ august.csvというデータ名で、各ツイートのデータを保存しました。
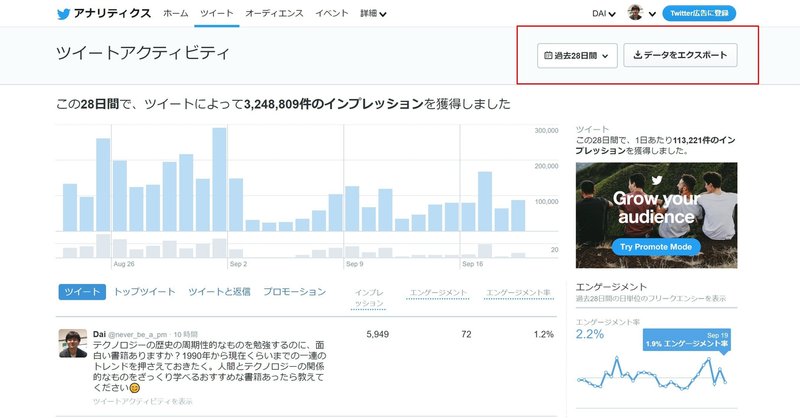
注意
現時点で自分のツイートを分析できない可能性が高いので、こちらのURLから僕のツイートのデータをダウンロードしてください。
https://drive.google.com/open?id=12x74y5GRCILXtgJsxoHXWJhU-hPmQOC-
Microsoft Azure Jupyter Notebookに登録
ツイートのデータと、フォロワーのデータを取得したら、Microsoft Azure Jupyter Notebookを利用します。MS Jupyter Notebookは、環境構築不要でノート形式でPythonが実行できる環境となります。Microsoftアカウントがなければ作成してください。
twitterというプロジェクト名を作成したら、今度は取得したapril.csvなどのファイルと、フォロワーのデータが入ったfollowers.csvというファイルをアップロードします。News → From computer → Choose file から、データを選択し、アップロードしてください。
アップロードに成功すると、以下のファイルがアップロードされます。
Jupyter Notebookを作成する
さて、ここまでできたらさっそくJupyter Notebookを作成しましょう。New をクリックしm、item Nameに任意の名前を付けます。さらに、Item TypeにはPython 3.6 Notebookに選択して、Newをクリックします。
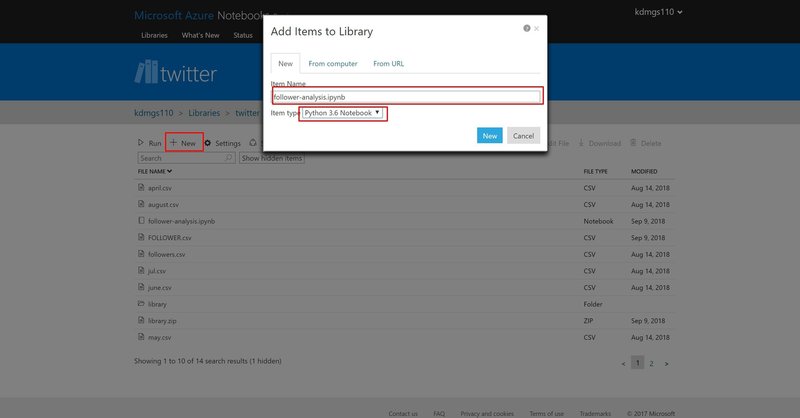
こうすると、新しくファイルが追加されているはずなので、そのファイルをダブルクリックします。そうすると、別のウインドで新しいノートブックが作成されているはずです。これで準備が完了です。

ライブラリのインポート
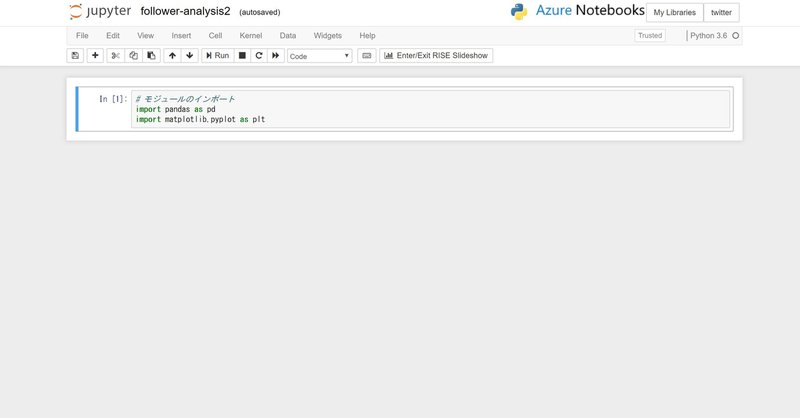
では、早速データの前処理をしたいと思います。データの前処理のライブラリのPandasと、matplotlibをimportします。
# モジュールのインポート
import pandas as pd
import matplotlib.pyplot as plt
lsコマンドで現在のファイルを見る
次に、現在のディレクトリの中に、挿入したCSVファイルが存在するか確認します。lsコマンドを利用すると、ディレクトリの中のファイルを確認することができます。ファイルがアップロードされていれば、april.csv等のデータを取得することができます。
!ls

CSVファイルの読み込みと、最初の5行の表示
次に、フォロワーのデータが入ったCSVファイルの読み込みをします。read_csvメソッドで、followers.csvファイルを読み込みます。headを使うと、読み込んだデータフレームの最初の5行を表示できます。
follower_df = pd.read_csv("followers.csv")
follower_df.head()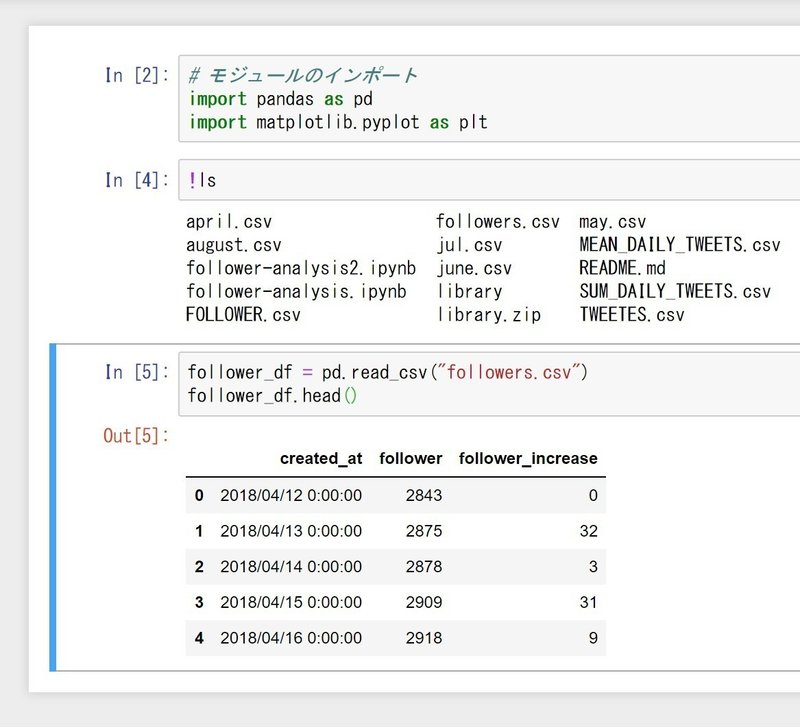
ツイートデータを読み込もう
次に、ツイートのデータにどんなものが入っているのかを確認してみましょう。4月のツイートのデータを読み込みます。
april_df = pd.read_csv("april.csv")
april_df.head()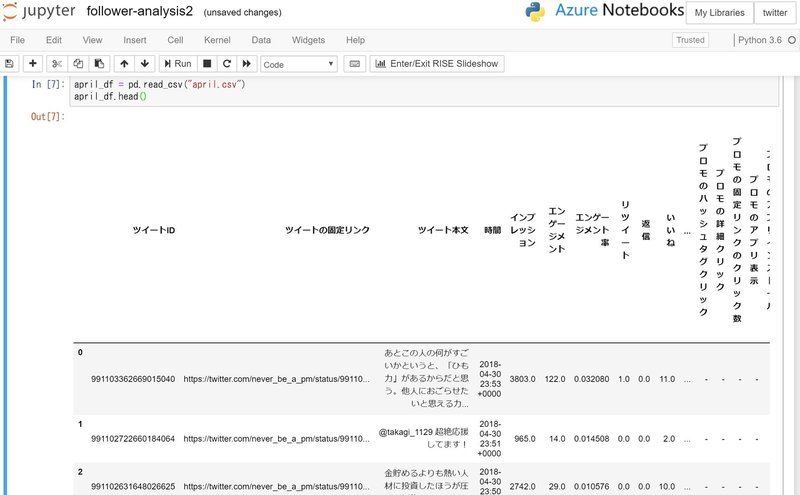
列名を取得
列名を全て、出力してみましょう。その前に、PandasのDataFrameという概念について説明しようと思います。今読み込んだCSVファイルは、DataFrameというに次元配列で保存されています。
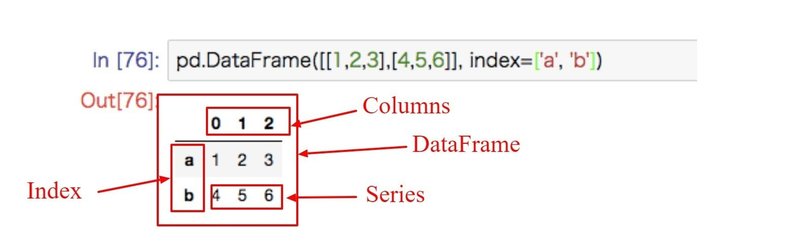
Dataframeは、IndexとColumnで構成されています。Columnsは列になりますね。Indexは行です。で、各IndexにはSeriesという行のデータが入っているようなイメージです。
列名のすべてを今見たいので、どこをみればいいのでしょうか。それは、columnsを見ればよいですね。なので、DataFrameから、Columnsにアクセスすれば取得できますね。
そこで、df.columns.valuesで、列名をリスト形式で取得することができます。
april_df.columns.values
出力結果は以下のようになります。

これだと配列でみにくいので、配列をfor文で一つ一つPrintすると、以下のようになります。
for value in april_df.columns.values:
print (value)
○ポイント
・read_csv("CSV名.csv")でファイルの読み込みができる
・df.head(行数)で、最初のN行を確認することができる
・df.columns.valuesでリスト形式で列名を取得することができる
フォロワー数のデータを棒グラフで表示する
さて、次にフォロワー数のデータを、グラフで表示します。
Pythonでグラフ表示するためには、大きく分けて二つの方法があります。
〇ポイント:Pythonでデータのグラフ表示をする際に使えるライブラリ
・Matplotlib: グラフ表示をかなり細かく詳細設定できるライブラリ
・Pandasのplot機能:Pandas上から簡易的にMatplotlibのグラフ表示ができる機能
個人的には、ちゃんとグラフィカルにレポートをするのであれば、ExcelやTableauなどのBIツールで表現すればよいと思うので、Python上ではあまりグラフ表示にこだわる必要はないと考えています。
なので、今回はPandasのplot機能を利用して、データビジュアライゼーションを行いたいと思います。
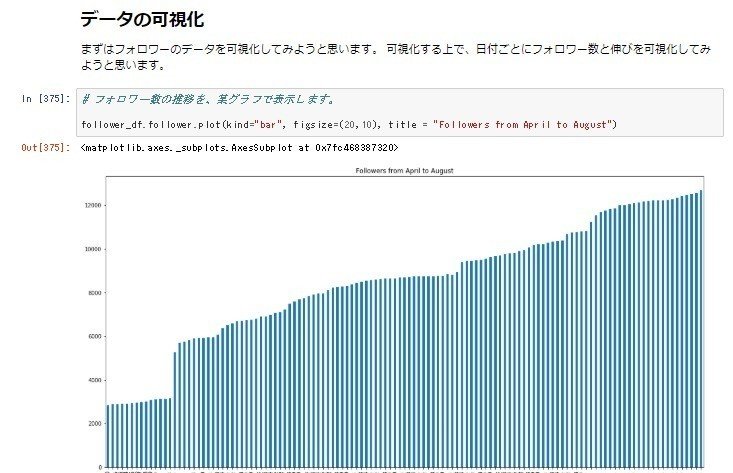
フォロワー数の推移を、棒グラフで表示してみます。まずはスクリプトをご覧ください。
follower_df.follower.plot(kind="bar", figsize=(20,10), title = "Followers from April to August")
各種オプションについて明記しておきます。
〇plotメソッド
- kind: グラフの種類。barは棒グラフ、scatterは散布図、ほかにもline(折れ線グラフ)などが存在する
- figsize: グラフの大きさ。タプル型で、横幅、縦幅の順に指定できる。
- title: グラフのタイトル。
出力結果は以下のようになります。
次に、フォロワー数の増加数を棒グラフで取得します。増加数が書いてあるデータはfollower_increaseという列に入っているので、そのデータを呼び出して、棒グラフで表示します。
follower_df.follower_increase.plot(kind="bar", figsize=(20,10), title="Follower increase in a day from April to August")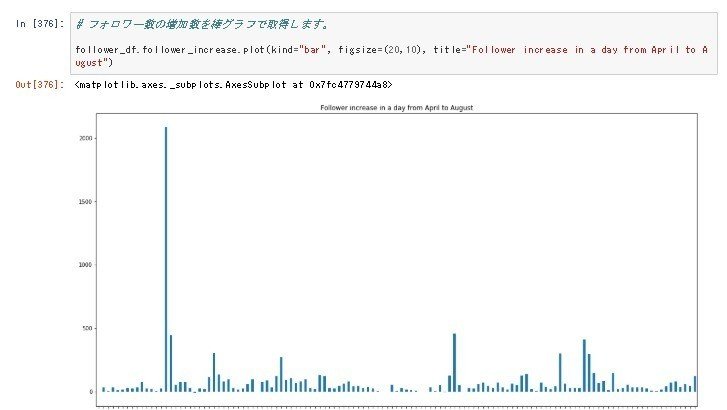
4-8月のツイートデータの結合する
フォロワーのデータをみたところで、今度は4-8月分のツイートのデータを結合します。今複数ファイルになっているので、一つにまとめます。
まずは、4-8月のデータを読み込みましょう。
april_df = pd.read_csv("april.csv")
may_df = pd.read_csv("may.csv")
june_df = pd.read_csv("june.csv")
jul_df = pd.read_csv("jul.csv")
august_df = pd.read_csv("august.csv")これらのデータフレームを、一つにまとめる方法として、Pandasのconcatメソッドがあります。複数のデータフレームを、一つにまとめるメソッドです。(画像は下記記事から引用しています。)
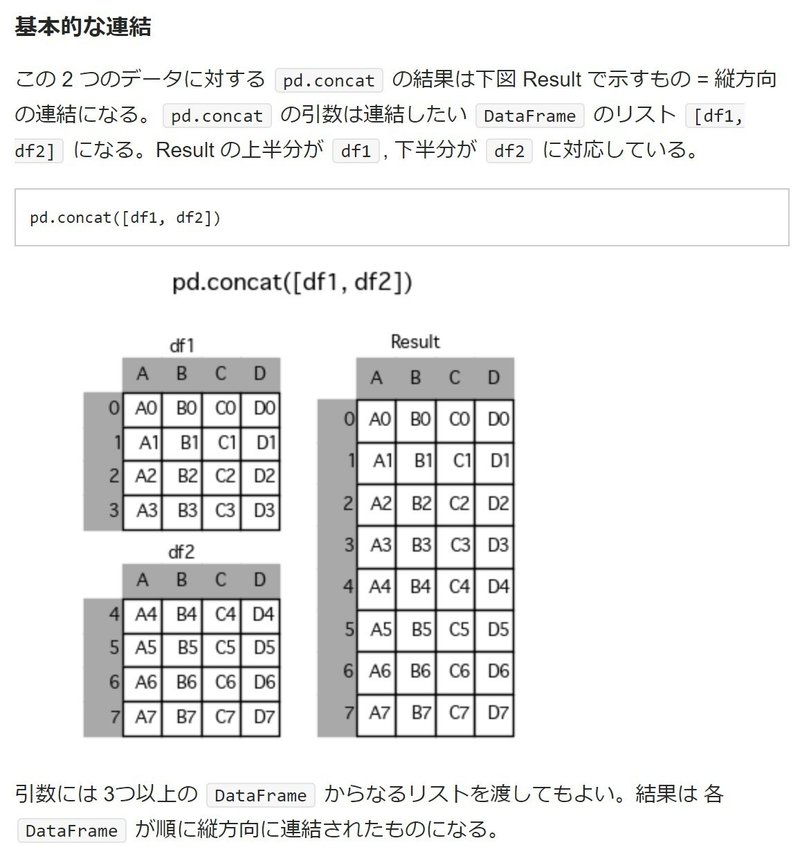
くわしくはこちらの記事を見るとよくわかると思います。
なので、 一緒にするデータフレームを一つの配列に代入します。
combine = [april_df, may_df, june_df, jul_df,august_df]その後、concatメソッドを利用して、データを結合します。
また、合成したデータフレームを、時間の早いものから順番に並べたいので、sort_valuesメソッドを利用します。
〇sort_valuesメソッド
・by: どの列名を基準に並び替えるかを決める
・ascending:降順にしたい場合は引数をFalse、デフォルトだと昇順になっています。
ここまでの流れを一気にやると、こんな感じになります。
tweets_df = pd.concat(combine).sort_values(by="時間")
tweets_df.head()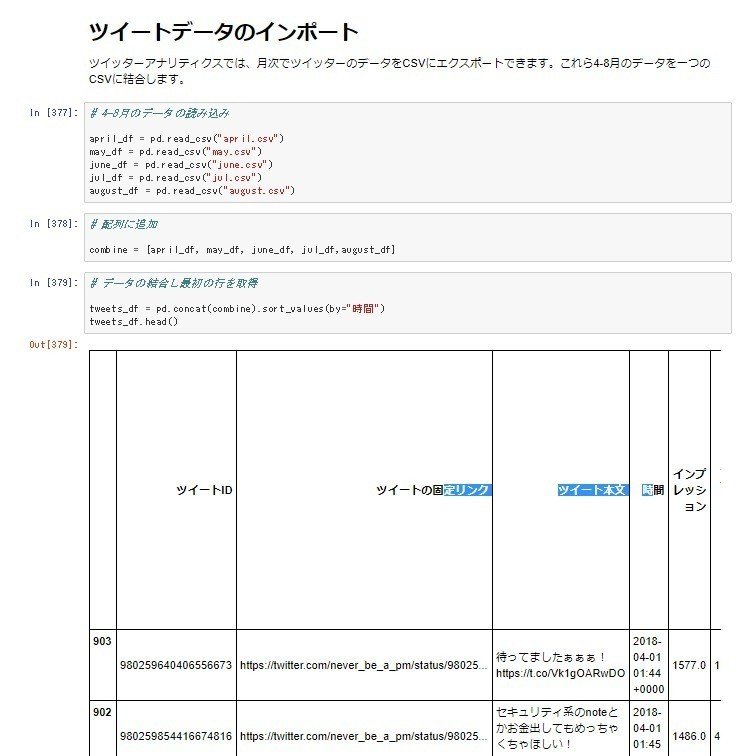
また、ちゃんと結合されたかを確認したいので、最終行を確認します。先頭行はheadで確認できましたが、最終行はtailで確認できます。
tweets_df.tail()
分析に必要なデータだけ抜き出す
さて、今ツイッターアナリティクス上から取得したデータがすべて表示されています。今回のデータの分析で必要なのは以下の通りです。
〇必要なデータ
・ツイート本文
・"時間"
・インプレッション
・エンゲージメント
・ "エンゲージメント率
・リツイート
・いいね",
・ユーザープロフィールクリック
・URLクリック数
必要なデータだけを取得するため、tweets_dfに再度代入し、表示します。
tweets_df = tweets_df[["ツイート本文", "時間", "インプレッション", "リツイート", "いいね", "ユーザープロフィールクリック", "URLクリック数"]]tweets_df.head()さて、時系列で取得したいので、再度時間でソートしてあげます。
tweets_df = tweets_df.sort_values(by="時間")URLが存在するかどうかを判断するデータを作成しよう
さて、ツイートの中にURLがあるツイートは、もしかしたら「有用だからほかの人にシェアしたい!」って思ってRTされる数が増えたりするかもしれないですよね。そこで、ツイートごとにURLが存在するかを0,1で入力できる特徴量を作成します。
やることは、
・tweets_dfの中の「ツイート本文」という列名の値に、「https]というキーワードが入っていたら1,はいっていなければ0を入力した「has_url」という新しい列名を作成し、その中に0,1の値をすべて入れる
という処理です。
tweets_df["has_url"] = tweets_df. ツイート本文.str.contains("http").astype(int)
tweets_df.head()詳しく説明すると、こうなります。
・新しくtweets_df["has_url"]とすることで、新しい列名を作成できるので、作成したものに代入するような形にする。
まず、「tweets_df.ツイート本文」で、ツイートの列名にアクセスします。
・ツイート本文に、httpsというキーワードが含まれている場合、True, 入っていない場合Falseを返すcontainsメソッドを使います
・Trueの場合は1, Falseの場合は0を返すastypeメソッドで、引数を整数(int)で返す処理をしています。

同様に、最後の行も確認します。
tweets_df.tail()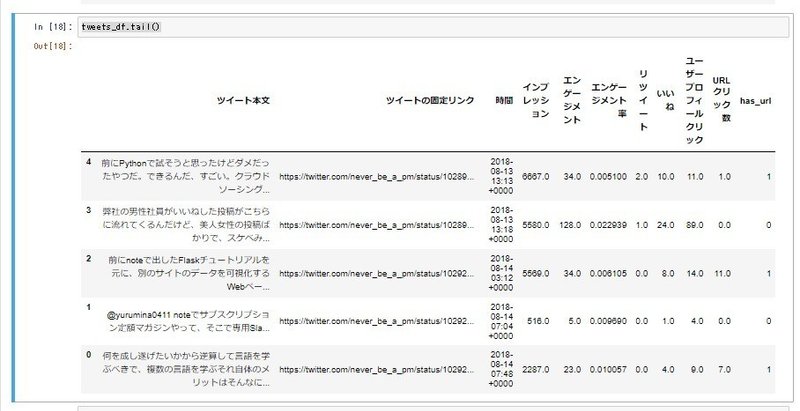
さて、全体でどれだけURLつきのツイートをしているのかを確認しましょう。その際に使えるのが、value_countsメソッドです。
value_countsメソッドは、データの個数が瞬時にわかるメソッドです。
tweets_df["has_url"].value_counts()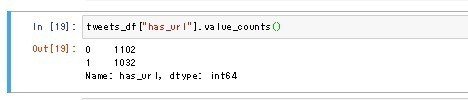
結果、URLつきが1032, なしが1102ということが分かりました。
箇条書きツイートがあるかどうか確認
次に箇条書きツイートがRT数を伸ばす説があるので、これも特徴量として取得してみましょう。さきほどと同様に見てみます。
tweets_df["has_point"] = tweets_df.ツイート本文.str.contains("・")
tweets_df["has_point"].value_counts()
なるほど、箇条書きツイートは219に対して、なしが1915。確かに毎回箇条書きツイートをしていたら、なんか偉そうでキモイですね。頻度としてはそれくらいなんだろうなぁというのが妥当な感じです。
「おすすめ」というキーワードが存在するかどうか確認
「おすすめ」というキーワードが存在するかを0,1で分け、集計してみます。また、グラフで可視化します。
tweets_df["has_recommendation"] = tweets_df.text.str.contains('おすすめ').astype(int)
tweets_df.has_recommendation.value_counts()
tweets_df.has_recommendation.value_counts().plot(kind="bar", title="recommendation")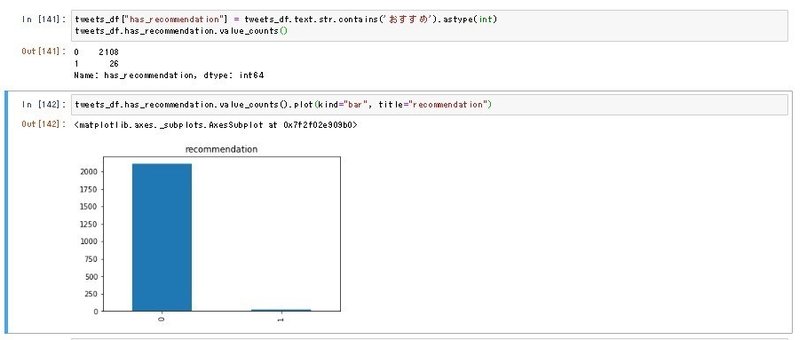
ツイートの文字数を確認
さて、今度はツイートの文字数が多ければ多いほど、リツイートされやすいかもしれないという説を検証するために、文字数を取得します。
文字数を確認するには、データフレーム.列名.str.len()で文字数を返してくれます。
# 文字数を表示する列名を表示します
tweets_df["tweets_len"] = tweets_df.ツイート本文.str.len()取得したツイートの文字数が全体でどんなものなのか、今度はヒストグラムに表示してみましょう。
tweets_df["tweets_len"].plot(kind="hist", figsize=(20,10), title = "Tweet length")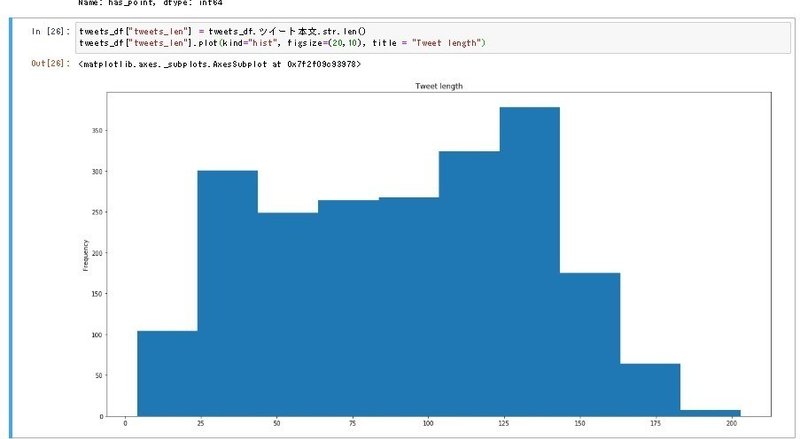
どうやら、話が長いようですね。平均をとってみます。平均を取る場合は、データフレーム.列名.mean()で取得できます。(meanは平均という意味です)
tweets_df.tweets_len.mean()
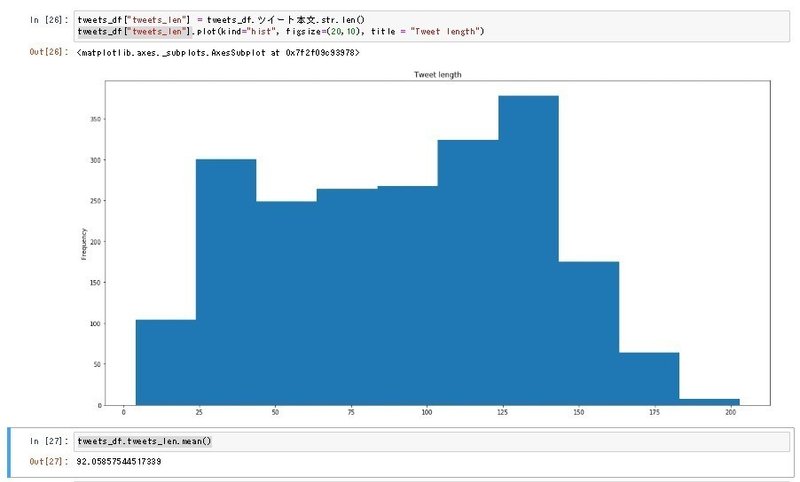
平均文字数は92文字らしいですね。
改行されているか確認する
次に、画面いっぱいだとクリックされやすい説を検証するために、改行コードの有無をデータで取得してみたいと思います。
tweets_df["nl_count"] = tweets_df.ツイート本文.str.count("\n")
tweets_df["nl_count"].value_counts()結果がこんな感じです。
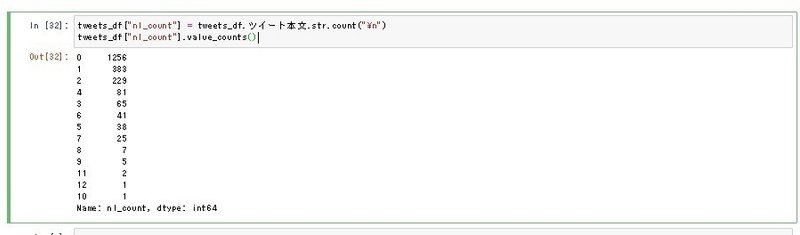
実際どのくらい改行されているのか、棒グラフに可視化してみましょう。
tweets_df["nl_count"].value_counts().plot(kind="bar", figsize=(20,10), title = "Number of New Line Code")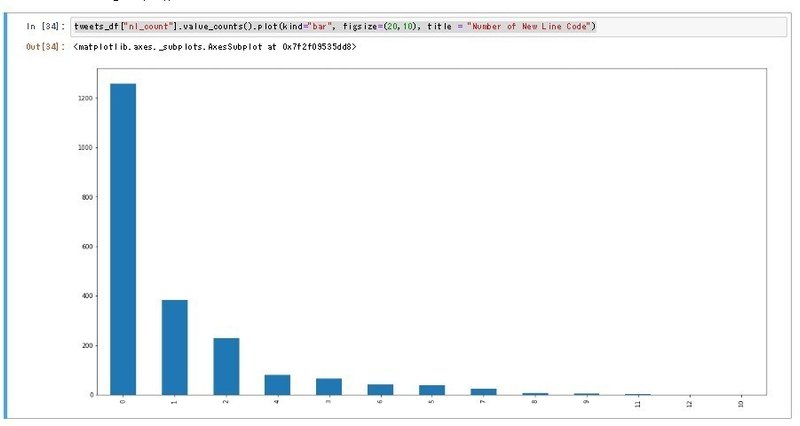
大体改行するにしても3つくらいみたいですね。
リツイートされやすいツイートの特徴を分析しよう
さてさて、フォロワー数が伸びる場合、リツイートがたくさんされているときが伸びやすいのは分かります。また、興味をもってプロフィールをクリックしてくれたら、そのあとフォローしてくれる確率も増えそうですよね。
ここから先は
¥ 2,980
サポートでいただいたお金はFanzaの動画を購入するために利用されます。