Courseraのデータサイエンス専門講座を受けた感想

Courseraのデータサイエンス講座を1コース受講してみました。受けてみた講座はJohns Hopkins大学が開講しているものです。今回はこちらの感想を書いていきたいと思います。
受講前に
上記講座は日本語対応していません。また、この講座ではいくつかの課題は他者の解答をレビューすることが条件になっています。なので日本語で講座を受けたい方や英語でのコミュニケーションに自信がない方は他の講座もありますのでそちらを探してみるといいと思います。また、想定される受講期間も約8ヶ月が想定されますのでかなりの長丁場になります。やりきる自信がない方は避けた方が良いと思います。
データサイエンスとは何か
こちらでの講座は最初にデータサイエンスとは何かを学びます。この講座ではデータサイエンスができることに、
●統計学、コンピュータサイエンス、数学
●データクリーニングと形式化
●データ可視化
になります。データサイエンスはこれらのスキルを使って日々増えていくデータを分析し、質問に答えることを要求されています。
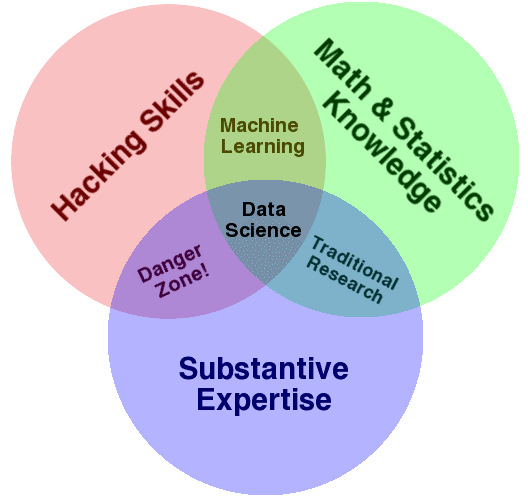
データサイエンスに求められるスキルの詳細は上記の画像のようになります。詳しくはこちらを参照にすると良いと思います。
データサイエンスが相手にするデータはその膨大さからビッグデータと呼ばれています。ビッグデータの品質はVolume、Velocity、Varietyの3つが求められます。ビッグデータは日々大きくなります。データは以前よりもさらに速く生まれ、データは様々なタイプを持っています。データサイエンスはこの品質を持ったデータを扱うスキルを身につけなければいけません。
また、データサイエンスは実際に活躍をしている人物を知るのも良い経験になります。この講座では、バスケットボールチームの監督をしたDaryl Moreyによる、Hilary MasonやFive Thirty Eightの記事を書いているNate Silverが紹介されています。
データサイエンティストがどのようにプロジェクトを進めているかは実際の事例を知るのが良いと説明しています。この講座ではHilary Parkerという有名なデータサイエンティストのブログを読むことが推奨されていますので、一度読んでみるといいと思います。
データとは何か
Cambridge English Dictionaryでdataについて調べると以下のように述べられています。
Information, especially facts or numbers, collected to be examined and considered and used to help decision-making.
一方Wikipediaは以下のように述べています。
A set of values of qualitative or quantitative variables.
この2つの違いをみますと、Cambridge English Dictionaryはデータを取り巻くアクションに焦点をあて、Wikipediaはデータに含まれているものに焦点をあてています。この2つの違いから、この講座ではデータに対してまず、値の集合について焦点をあて、次に変数について注目し、最後に変数の量と質に注目すると良いと説明しています。
データサイエンスにとってデータは確かに重要ですが、それ以上に重要なのは質問することです。データサイエンティストはまず質問し、それに答えるためにデータを探します。まず質問や疑問を明らかにすることが重要で、データは質問や疑問を促すものではないということを認識することが重要です。
データサイエンティストが答える質問
データサイエンティストが質問に対して行うタスクは以下のようになります。
●記述分析
●探索分析
●推論分析
●予測分析
●因果分析
●メカニズム
記述分析とは、データ集合の要約を作ることです(例:国勢調査)。このタスクは記述統計に詳しくなる必要があります。例えば平均や分散、中央値などです。
探索分析とは、データから未発見の関連を見つけ出すことです。この考えは「相関関係は因果関係を意味するものではない」というフレーズが根底にあります。注意しなければいけないのはこのタスクは関連を発見することで、原因を発見することではないことです。なのでこの段階では質問に対する最終的な答えにはなりません。
推論分析の目的は、小さなデータサンプルから一般的な母集団を推測することです。推論分析の目標は統計モデリングです。記述的では国勢調査などが例として挙げられますが、推論ではそのようなデータを用いるべきではありません。国勢調査は人口全体に関する情報になるためです。ここではそのサブセットを扱うべきです。
予測分析では、現在のデータから将来のデータについて予測することです。基本的には過去現在のデータからパターンを見出し、将来の可能性について予測することが主になります。予測では変数の適切さが重要になります。予測は一般的にとても難しく、そもそもその予測を評価すること自体が難しいです。
以上の分析では実は相関関係しかみることができていません。ここでの目的はある変数を動かした時に何が起こるかをみることです。この分析はデータだけで行うのは非常に難しく、大抵は因果分析を行うことができません。通常はランダム化比較試験(RCT)で分析されます。
メカニクスは現在ではそれほど注目されていない分析です。この分析の目標はある変数の変化が別の変数に与える影響を正確に測ることです。単純な問題、または決定論的な方程式がない限りは非常に複雑な問題になってしまいます。
まとめ
講座の内容はとても内容が良く、分かり易かったと思います。全て英語ですが、平易な英文で説明されているため、単語さえ分かれば問題なく理解できる内容だと思います。
実際の講座ではRCTについてより詳細な説明がされていますが、内容が高度になるためここでの説明は省きたいと思います。また、p値の危険性についても触れています。これはData dredgingというWikipediaのページも作られ議論が盛んに行われているため、知っておくと良いと思います。
また、この講座ではデータサイエンティストが用いるツールとしてR言語とRstudio、Githubの使い方まで説明されていますが、この記事は省略したいと思います。
追記
RstudioとGithubは連携することができます。この連携がかなり優秀で、Sourcetreeと同じ感覚で使うことができます。Github側でsshキーを登録しておけば簡単に連携できますので、試してみるといいと思います。
この記事が気に入ったらサポートをしてみませんか?