Pythonで作る楽天リサーチツール

はじめまして、コリパン(@poikatsuhack)です。普段はTwitterで楽天市場を中心にポイントせどりを趣味でやっています。初めて、noteというプラットフォームで記事を書きます。
今回、作るのは実際僕が使っている楽天のリサーチツールをダウングレードしてシンプルにしたものの作り方を解説していきたいと思います。ダウングレードした理由は一気にやっても挫折することが目に見えているからです。
このNoteはせどらー向けですが、そこからプログラミング沼に引き込むためのNoteです。多分最初は苦労すると思いますが、プログラミングができれば僕のように人生変わる人もいますのでこの記事をきっかけに人生変わる人が100人中1人くらい(これはオンラインプログラミングスクールで最終的にプログラミングができるようになる人の数です。)でいいので出てきてほしいなと思い筆を執りました。値上げするつもりも有料にするつもりもサロンに誘導する予定もないので安心してください。
要件
今回の要件は以下のようになります。
1.CSVファイルからデータを読みこむ
2.楽天APIを使ってデータを取得
3.参考価格>楽天価格*0.9の商品のリストを作成しCSVファイルに落とし込む
削った機能
1.最新の参考価格取得機能
理由:スクレイピングを大量に行うと業者に迷惑がかかるため
2.NGワード機能
理由:プログラミングは万能でないことを知ってもらうため
楽天DevelopersからアプリIDの発行
https://webservice.rakuten.co.jp/にアクセスします。
アプリID発行をクリックして楽天IDでログイン処理を行います。
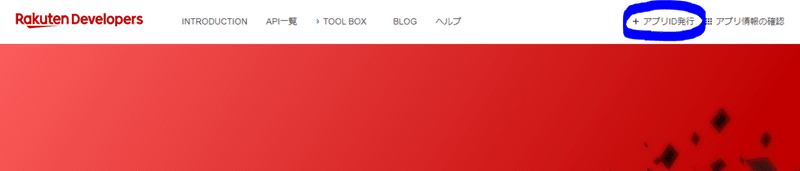
入力を進めていきます。URLの部分は何でもいいです。https://google.comでも通ります。
すると以下のような画面が表示されます。
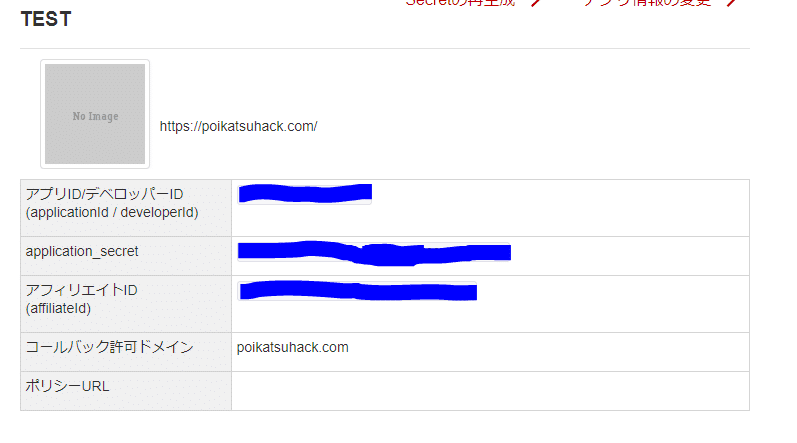
アプリIDとapplication_secretは今後使うのでメモを取っておいてください。
CSVの作成
ここで生命線となるCSVファイルを作成しましょう。本当は、ここはリアルタイムで業者のデータを取得してリストを作るべきですが、色々アレなので手作業でデータを打ち込むという形にしています。
こちらにサンプルデータがありますのでこちらをCSV形式でダウンロードしてみてください。
サンプルコードで動かしてみよう
ここに完成プログラムがあるのでそちらを動かしてみましょう。
ページを開いたら左側のファイルアイコンをクリックして下さい。
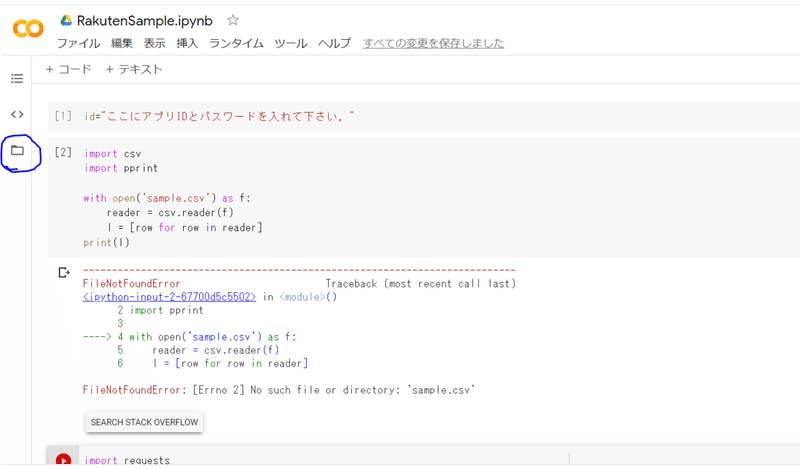
そしてアップロードを選択して先ほど作ったsample.csvをアップロード下さい。
id="ここにアプリIDとパスワードを入れて下さい。"
に先ほど登録したアプリケーションIDとパスワードを入力して下さい。
必ず”ダブルクォーテーションで囲って”下さい。
例:id="12345678910"

それが出来たらランタイムで実行してみましょう。プログラムが動いたと思います。完了したらsample.csvをアップロードしたときにクリックしたファイルアイコンをクリックしましょう。to_csv_out.csvというファイルが出来ていたら完成です。おめでとうございます。
コード解説
それでは順番にコードを読んでいきましょう。
id="ここにアプリIDを入れて下さい。"idという変数を定義してその中にアプリIDを入れます。
変数:変数とは便利なラベルなようなもので、長いURLなど再利用するときに用います。
import csv
importでライブラリを読み込みます。ここではcsvを読み込むためのcsvライブラリを読み込んでいます。余談ですが、Pythonが人気があるのは機械学習などのライブラリが充実しているためです。
with open('sample.csv') as f:
reader = csv.reader(f)
l = [row for row in reader]
1行目は、openでCSVファイルを開きfというオブジェクトに格納しています。そして、csv.reader(f)でcsvファイルの内容を読み取っています。最後の行はlという変数に[row for row in reader]と書いて1行づつcsvファイルを取り出しリストに格納しています。この[]で囲まれた書き方をリスト内記法といういいます。
l = [row for row in reader]
以下と同じ
l=[]
for row in reader:
l.append(row)また、インデントが下がっているのがわかると思います。最初は分からないと思うので:がついたあとはインデントを下げると思ってもらえれば良いと思います。
import requests
import json
import pandas as pdこれらは、それぞれ外部ライブラリを読み込んでいます。requestsはHttp通信をするライブラリ、jsonは、json形式を読み込むライブラリ、pandasは、データをごにょごにょしやすくするためのライブラリになります。
df = pd.DataFrame()pandasのデータフレームという形式で空のデータフレームを定義しています。
for i in l[1:]:
print(i)
url = "https://app.rakuten.co.jp/services/api/IchibaItem/Search/20170706?format=json&keyword="+row[1]+ "&applicationId="+id
a = requests.get(url)
b = a.json()先ほど読み込んだデータlから1行ずつ取り出しています。
l[1:]となっている理由は1行目はヘッダーでデータが入っていないためスキップして2行目から処理するようにしています。