
アヤメのデータ分析

1.はじめに
IT業界に携わって30年。
なにやら、世の中が「DX」と騒がしくなってきた。
会社が副業を推奨しだしたので、何か小遣い稼ぎができる方法を模索した結果、Aidemyの受講となった。
2.本記事の概要
・どんな人に読んで欲しいか
副業をしたい人
DXについて分からない人
・この記事に書くこと、わかること
Aidemyデータ分析コースの成果物(アヤメのデータ分析)
データ分析の流れ
・この記事で扱わない事
データの加工
3.作成したブログラム
成果物作成に当たって、身近にデータがなく、
サイキットラーンに、アヤメのデータがあるので、
それを使って、データ分析を行うことにした。
実行環境:グーグルコラボ
いきなり、Pythonのコードから入る。
各先生方の呼び出し。
Pythonには沢山の先生方、呪文があって、
それぞれ用法があります。
# ナンパイ先生、サイパイ先生、パンダス先生の召喚
import numpy as np
import numpy.random as random
import scipy as sp
import pandas as pd
from pandas import Series, DataFrame# サイキットラーン先生のデータ分割術を召喚
from sklearn.model_selection import train_test_split
# サイキットラーン先生が持ってるアヤメさん’sの召喚
from sklearn.datasets import load_iris
# アヤメさん’sの移動
iris = load_iris()
# アヤメさん’sを行列計算部屋に入れる
df = pd.DataFrame(iris.data, columns=iris.feature_names)
# アヤメさん’sに本名を加える
df["target"] = iris.target_names[iris.target]
# 行列計算部屋に入って、本名が加わったアヤメさん’sはこんな感じ
df.head()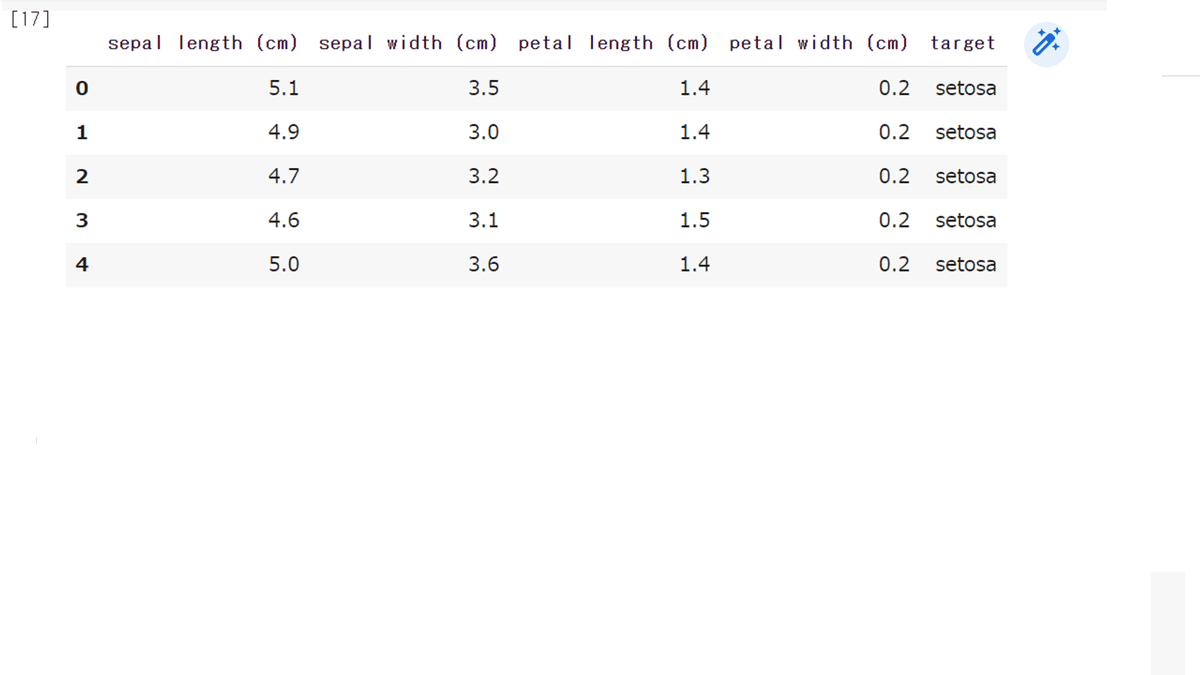
ここまでで、アヤメのデータを150件分読み込みました。
アヤメの種類は3種類で、
各種類50件ずつ格納されています。
sepal length (cm) がく片の長さ
sepal width (cm) がく片の幅
petal length (cm) 花弁の長さ
petal width (cm) 花弁の幅
上の4つの特徴を使って、下の品種を学習します。
“setosa”, “versicolor”, “virginica” という 3 種類の品種
果たして、50件ごときで学習できるのか?
# アヤメさん’sを本名と本名以外に分ける
X = df.drop('target', axis=1)
Y = df['target']
#更に、学習用とテスト用に分ける
X_train, X_test, y_train, y_test = train_test_split(X, Y, random_state=0)K近傍法
票田を指定して、多数決で何の種類か決めます。
ここで言う票田とは、総票数1から10の世界。
総票数10なら、6票取った種類がそこの票田を支配します。
アヤメさん頑張れ。
# マットプロットリブ先生の召喚、サイキットラーン先生のK-近傍術を召喚
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
# 多数決の総票数の範囲(1から10)
k_list = [i for i in range(1, 11)]
# 正解率を格納する空リストを作成
accuracy = []
# 多数決の総票数を変えながらモデルを学習
for k in k_list:
model = KNeighborsClassifier(n_neighbors=k)
model.fit(X_train, y_train)
accuracy.append(model.score(X_test, y_test))
# 正解率のグラフ
plt.plot(k_list, accuracy)
plt.xlabel("n_neighbor")
plt.ylabel("accuracy")
plt.title("accuracy by changing n_neighbor")
plt.show()
票田が変わっても、結果が変わりません。
同じ種類がそれぞれ凝り固まっている状態でしょうか。
正解率97.5%くらい。
次に、非線形SVMを使って正解率を見ていきます。
非線形SVMは、分類の一般化による予測の向上が見込めます。
※分類というのは、ラベルを付けて学習させる教師あり学習の一形態で す。
※教師あり学習というのは、ラベルとデータが対になっていて(教師)、
それを使って学習させる方法です。
学習や予測が遅くなるので、データが多い場合はやめた方が良いでしょう。
今回は幸い150件しかないので、いきます。
# サイキットラーン先生の非線形SVMを召喚
from sklearn.svm import SVC
from sklearn import preprocessing
# 学習時の誤り許容度の範囲を設定(今回は1/100000,1/10000,1/1000,1/100,1/10,1,10,100,1000,10000)
C_list = [10 ** i for i in range(-5, 5)]
# 正解率を格納する空リストを作成
train_accuracy = []
test_accuracy = []
# 学習時の誤り許容度の応じた正解率の計算
for C in C_list:
model = SVC(C=C, random_state=0)
model.fit(X_train, y_train)
train_accuracy.append(model.score(X_train, y_train))
test_accuracy.append(model.score(X_test, y_test))
# 正解率のグラフ
# semilogx()はxのスケールを10のx乗のスケールに変更する
plt.semilogx(C_list, train_accuracy, label="accuracy of train_data")
plt.semilogx(C_list, test_accuracy, label="accuracy of test_data")
plt.title("accuracy with changing C")
plt.xlabel("C")
plt.ylabel("accuracy")
plt.legend()
plt.show()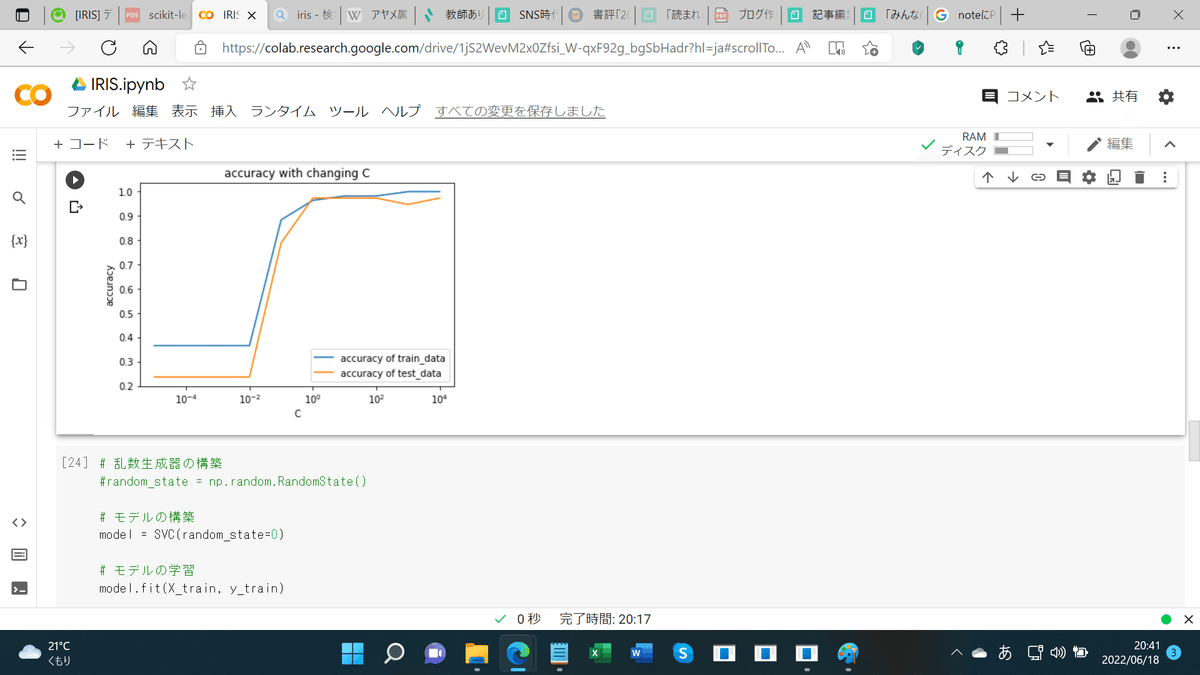
上のグラフのCというのは、学習の誤りの許容度で、
分類の一般化に当たって、どのくらい間違いを認めるか。
一般化なので、ざっくりやった方が上手くいきます。
分類を厳密にやり過ぎると(C=1/1000、1/100)、
正解率が上がっていません。
95%くらいでしょうか。
グラフではよく分からないので数字で出しました(下図)。
97%でした。
# 乱数生成器の構築
#random_state = np.random.RandomState()
# モデルの構築
model = SVC(random_state=0)
# モデルの学習
model.fit(X_train, y_train)
# 検証データに対する正解率を出力
print(model.score(X_test, y_test))実行結果
0.9736842105263158
次に、ランダムサーチです。
データ分析には、ハイパーパラメーターというオプションが沢山あります。
やってて、何を選ぶかよく分からないので、
お任せモードとして、ランダムサーチがあります。
面倒くさい時には、これで一気に片付けましょう。
# サイキットラーン先生のランダムサーチを召喚
import scipy.stats
from sklearn.model_selection import RandomizedSearchCV
from sklearn.metrics import accuracy_score
# ハイパーパラメーターの取りうる値の範囲
model_param_set_random = {SVC(): {
"kernel": ["linear", "poly", "rbf", "sigmoid"],
"C": sp.stats.uniform(0.00001, 1000),
"decision_function_shape": ["ovr", "ovo"],
"random_state": [0]}}
max_score = 0
best_param = None
# ランダムサーチでハイパーパラメーターを探索
for model, param in model_param_set_random.items():
clf = RandomizedSearchCV(model, param)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
score = accuracy_score(y_test, y_pred)
if max_score < score:
max_score = score
best_param = clf.best_params_
print("ハイパーパラメーター:{}".format(best_param))
print("ベストスコア:",max_score)
svm = SVC()
svm.fit(X_train, y_train)
print()
print('調整なし')
print(svm.score(X_test, y_test))実行結果
ハイパーパラメーター:{'C': 916.0452370334326, 'decision_function_shape': 'ovr', 'kernel': 'linear', 'random_state': 0}
ベストスコア: 0.9736842105263158
調整なし 0.9736842105263158
勝手にハイパーパラメーターを決めて、
勝手にハイスコアを叩き出してくれます。
97%です。
結局、全て97%でしたね。
各品種50件しかデータがないのに、
しかも更にそれを、学習用とテスト用に分けてるのに。
多分、40件分くらいしか学習してない。
グーグルコラボを使えば、誰でも上のコードを実行すれば出来るのでやってみて下さい。
4.今後の活用
あまり学習時間を取れなくて、課題提出で終わってしまいそうです。
データサイエンティストとして副業したいので、
ツイッター等をチェックしながら、アンテナ張っていきます。
デジハリオンラインは修了していないのに求人来るけど、
アイデミーはあまり来ないなあ。
5.おわりに
講師の方々のお陰で何とか終わりそうです。
もくもく会やオンライン学習室等をもっと活用すれば良かった。
受講期間が終わったら講師に聞けないので、
物怖じしている時間はありません。
講師の方々、視聴者の方々、その他の皆さん、大変ありがとうございました。お陰様で給付金ゲットできそうな気がしてきました。
Outsystemsという会社が、データサイエンティストが失業するというようなことを言ってますが、ローコード、ノーコード業界、その他も睨みながら
みんなの努力が無駄にならない社会にします。
この記事が気に入ったらサポートをしてみませんか?