
【41日目】100日後にベイズ統計ができるゆーみん

こんばんは!
今日もごはんが美味しくて幸せでした☺️
今日は『行動データの計算論モデリング』第5章をやっていきま〜す!
第5章は『モデル選択』です✨
大事ですね〜(全部大事だけど)
複数のモデルから最適なモデルを選択する方法が紹介されています。
AICとかBICとかですね。
※ サポートページに掲載されているコードを使用しています。私本人の解読のためにRコードとStanコードを行ったり来たりしていて大変わかりにくくなっております。詳しくは↓まで!
今回は
❶ 選択されなかった選択肢の価値は更新されない標準的なQ学習モデル
❷ 選択されなかった選択肢の価値が一定の割合でゼロに近づいていくことを仮定した忘却率と学習率が同じforgetting-Q(F-Q)学習モデル
❸ 忘却率と学習率は異なる値を取りうるとするdifferential forgetting-Q(DF-Q)学習モデル
以上のモデルを比較していきます。
データはシミュレーションにより真のモデル(今回は学習率、忘却率が共に0.4のF-Qモデル)に仮想的な200試行分の選択課題を遂行させて生成していきます。まずは一人のデータから↓
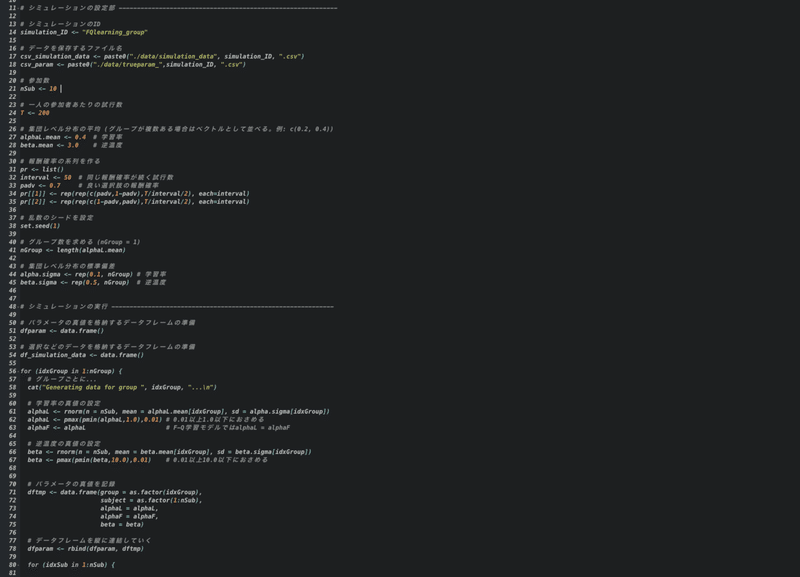
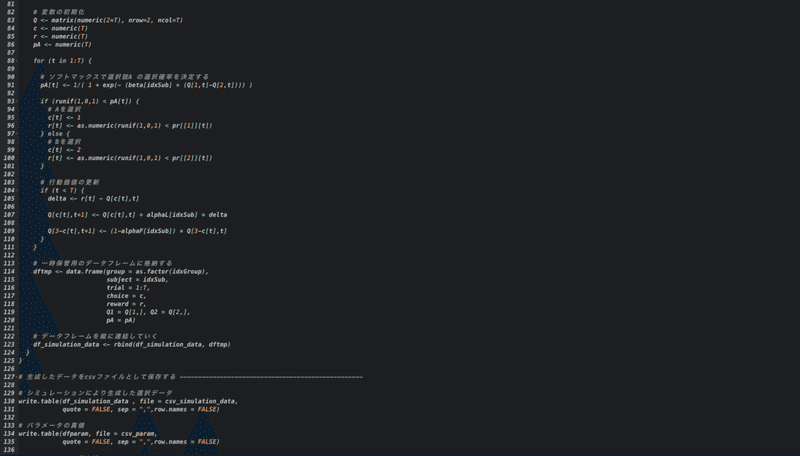
ここで対数尤度が最も大きいモデルはDF-Q学習モデルとなります。
対数尤度はパラメータ数が増えると大きくなる傾向があり、
3つのモデルのなかでDF-Q学習モデルがパラメータ数が多いので
オーバーフィッティングが起きていると考えられます。
その場合、対数尤度にパラメータ数に応じたペナルティを課すなどします。
そのようにモデルの良さを測るのが情報量基準!
ここでは計算論モデリングにおいてよく用いられる
・赤池情報量基準(AIC)
・Schwarzのベイズ情報量基準(BIC)
が紹介されてました!
コード載っています!わーい!
な、長い()
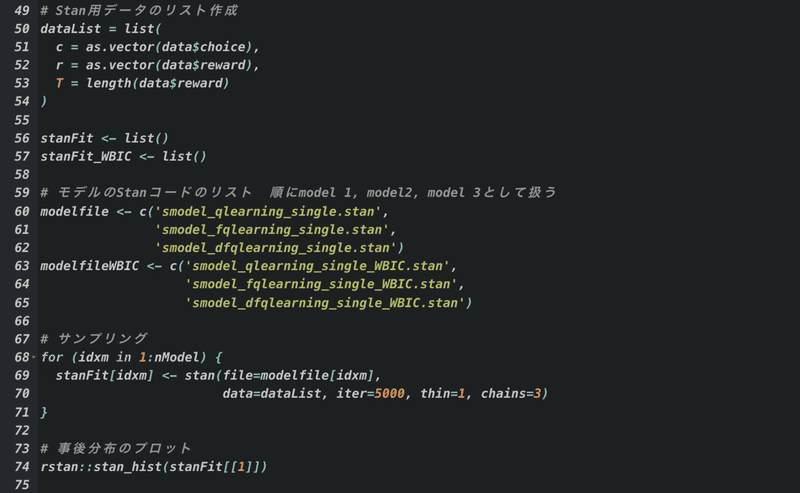
作成したデータ(さっきのシミュレーション)を読み込み,各種のモデル選択をします↓
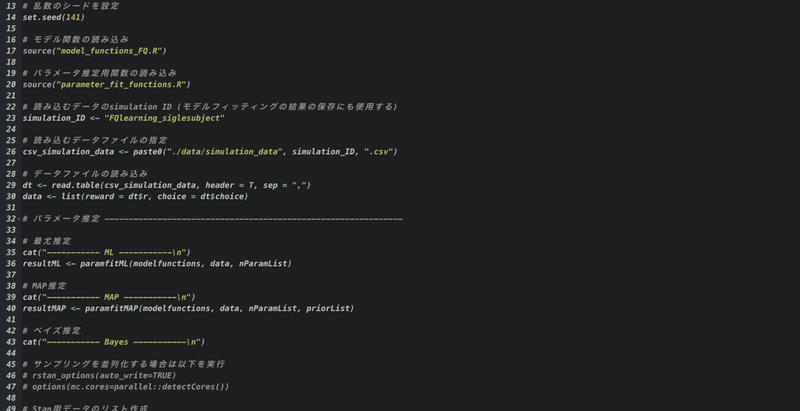
モデル関数を格納したRファイルに加えて、
ベイズ推定およびWAICの計算用、WBICの計算用のStanコードが3つずつ!(わかりやすいように分けてくれています。ありがてぇありがてぇ)
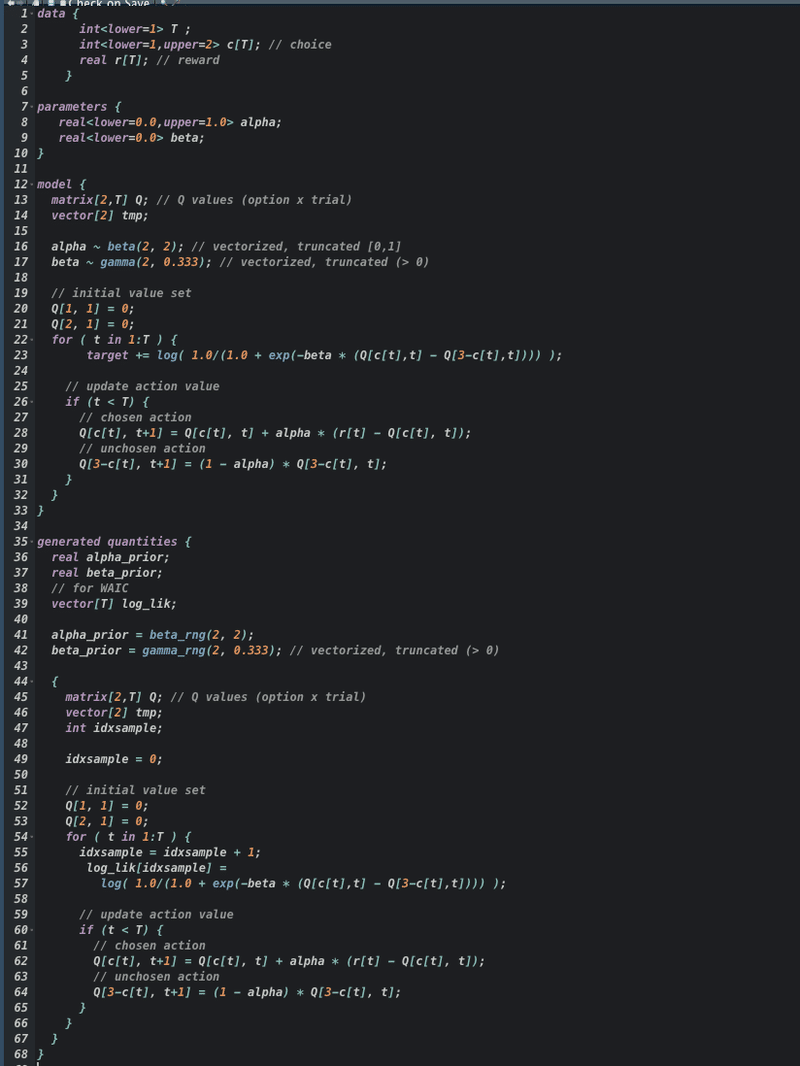
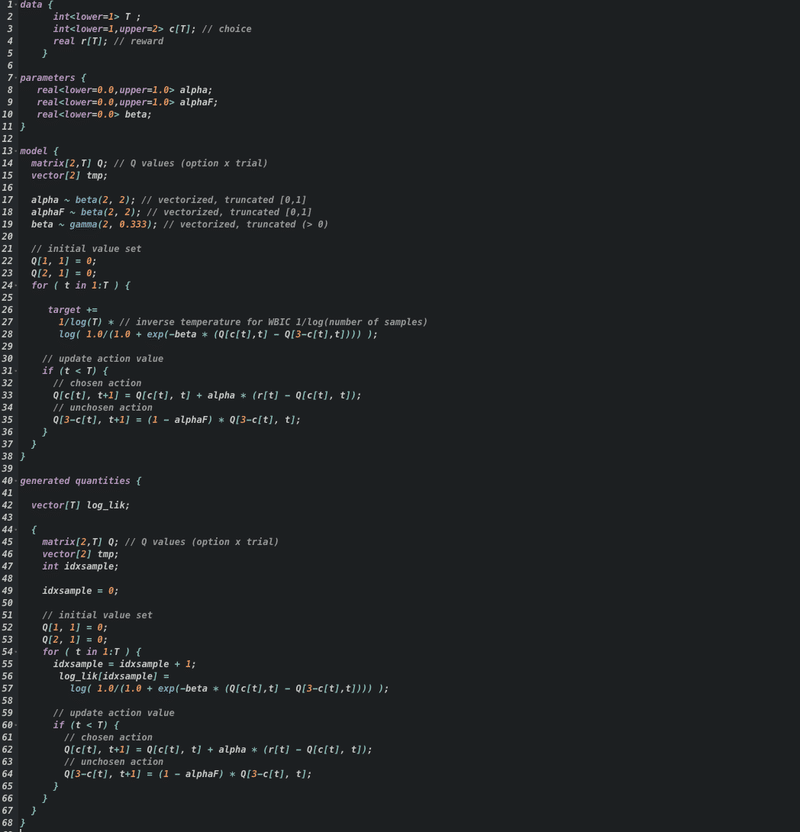
ベイズ推定およびWAICの計算用のStanコード(Q学習モデル)↓
ベイズ推定およびWAICの計算用のStanコード(F-Q学習モデル)↓
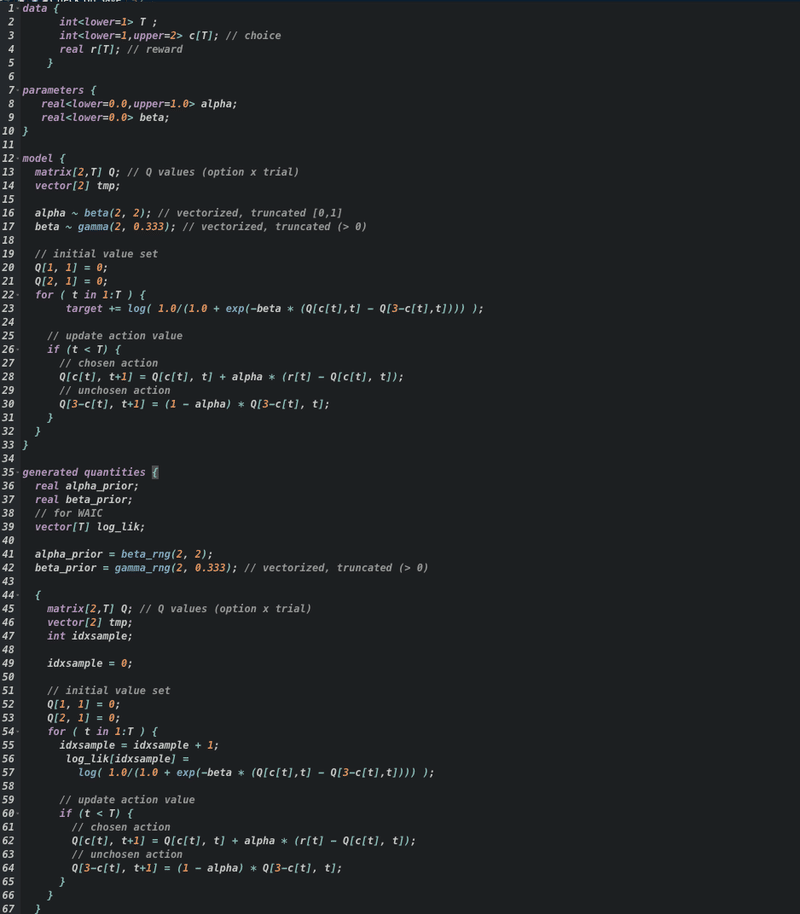
ベイズ推定およびWAICの計算用のStanコード(DF-Q学習モデル)↓
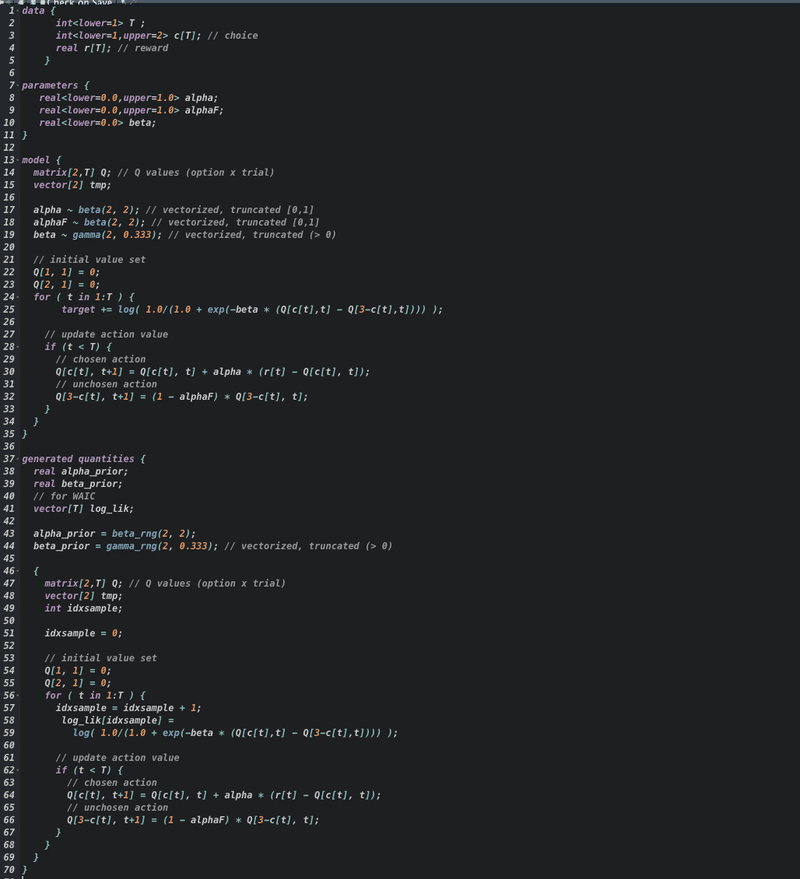
WBICの計算用のStanコード(Q学習モデル)↓
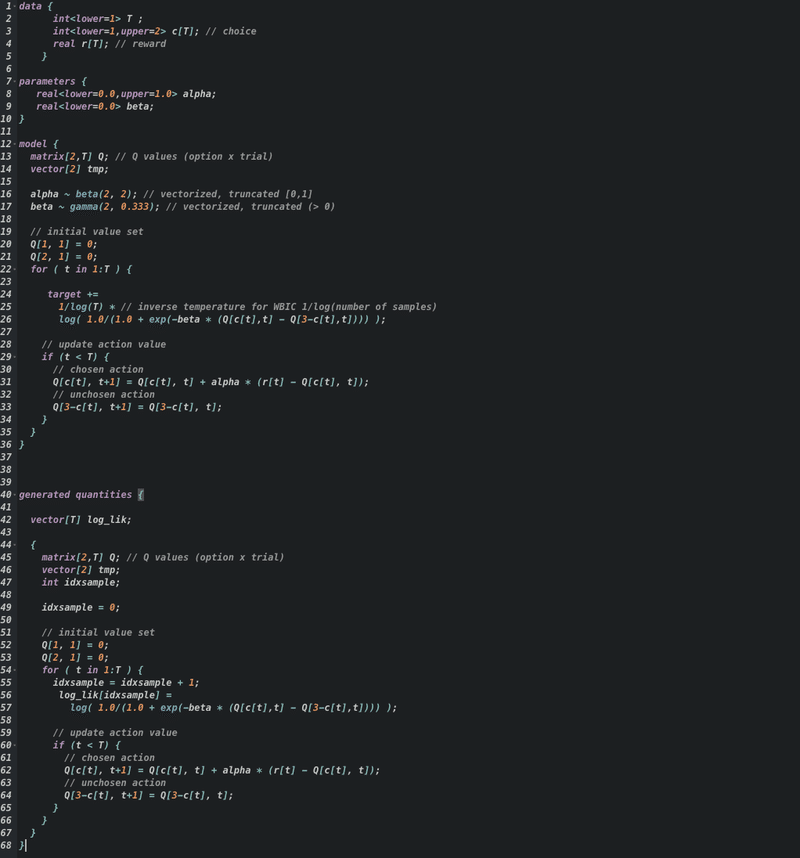
WBICの計算用のStanコード(F-Q学習モデル)↓
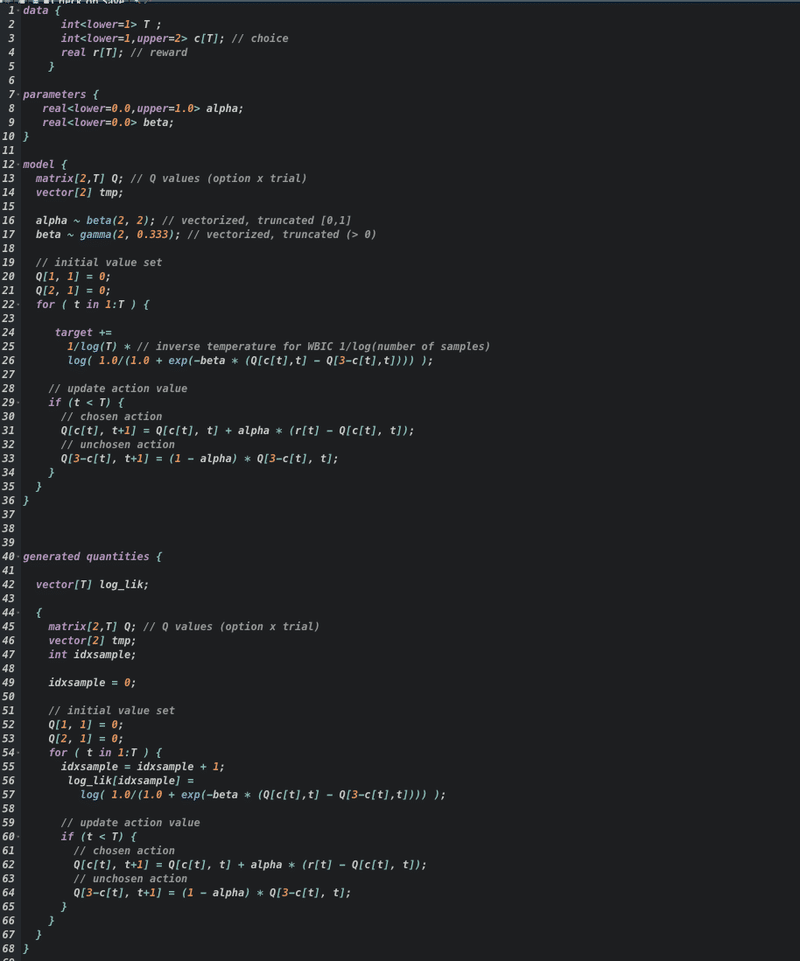
WBICの計算用のStanコード(DF-Q学習モデル)↓
で、このStanファイルをRで読み込んで〜↓
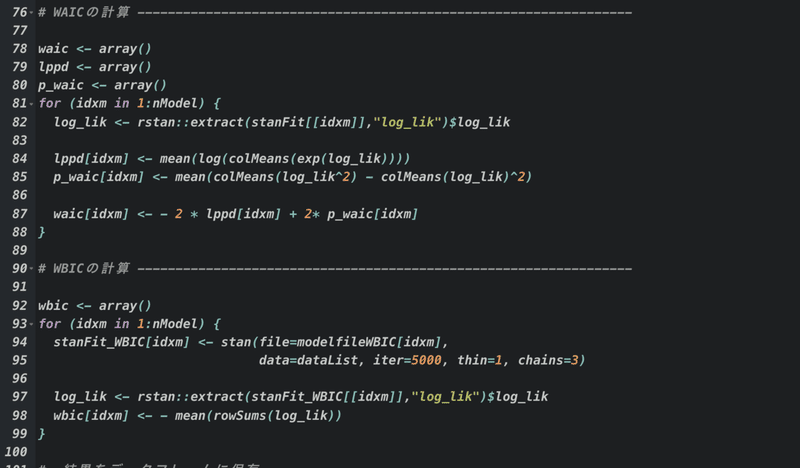
WAICとWBICを計算↓
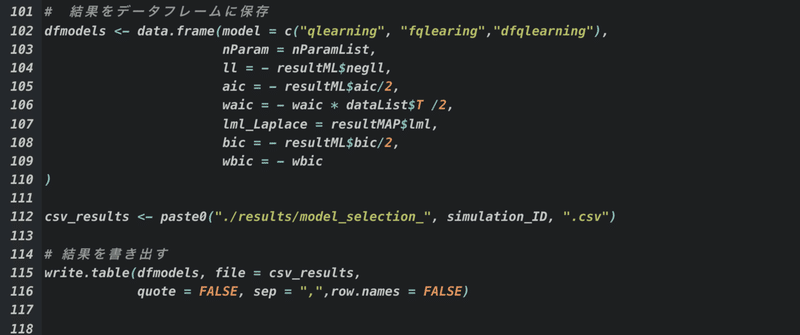
あとは結果をデータフレームに保存したり、
結果を書き出したりですね〜
ながっっっっと思いましたが、解読すれば意外といける???
しかし自分で書く未来図が想像できませんね(白目)
今日はここまで!
また明日お会いしましょう〜
あと59日
この記事が気に入ったらサポートをしてみませんか?