
【Text-to-Image】AI画像生成で桃太郎を4コマ画像要約してみた【DALL・E 2/Midjourney/StableDiffusion】

はじめに
こんにちは。メディア研究開発センター所属の新美です。
私は小さい頃から大の漫画好きでして、学生時代、歴史の勉強はほとんど漫画で覚えていました。活字だけで読むよりも漫画などでイラストと一緒に読む方が頭に入るんですよね。(新聞社に勤めている身としてはいかがなものかと思われますが)
そんなわけで全ての読み物に挿絵がついていたり、文章を画像で要約してくれたらいいのにな〜と昔から思っていたのですが、なんとAIで実現できる未来がすぐそこまできているかもしれないのです。そこで、今話題の画像生成AIについて調査・比較していきたいと思います。
Text-to-Image
文章から画像を生成するタスクは、「Text-to-Image」と呼ばれています。Text-to-Imageとは、その名の通りText(文章や単語)を条件として、その条件に合うImage(画像)を生成する技術のことを指します。
なぜテキストから画像生成?
Text-to-Imageの応用先としては、次のものが挙げられています。
アートの生成
コンピュータ補助によるデザイン設計
画像編集
マルチモーダル学習の発展
ビジョンと言語の関連付け
具体的には音声で画像を修正したり、脚本からアニメを生成するといった応用も考えられます。私は美的センスが皆無なので、こんな素人でもテキストの入力だけでアートが作り出せたり、お洒落なデザインが簡単に描けるようになると思うと実に興味深いですね。
Text-to-Imageの歴史
画像生成の代表的な手法にはGAN,VAE,Flow-basedなどがありました。GANを使った手法では2018年に高精細な画像を生成することで話題になった「BigGAN」が発表され、VAEベースの「VQVAE」やFlow-basedの派生で「Glow」など様々な手法が登場しました。一方で与えられたシグナルから徐々にノイズを取り除くことで画像を生成するDiffusion Modelは、GANを凌ぐ高精細な画像を生成することができるとして近年再度注目を浴びています。
そしてこのDiffusion Modelと、汎用画像分類モデルのCLIPを用いた「GLIDE」や「DALL・E2」が登場し、CLIPを用いずに大規模言語モデルを使用した「Imagen」など次々に新しい手法が提案されており、今非常にホットな分野であることがわかります。
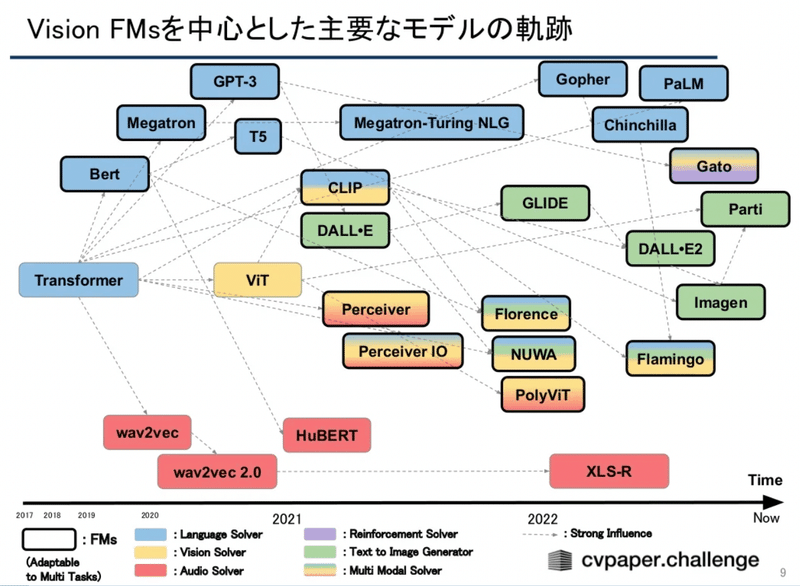
今話題のモデルを試したい!
次々と新しい手法が発表されていますが、今話題の最新のモデルでいくつか画像生成を試してみたいと思います。今回は誰もが知っているであろう童話「桃太郎」の画像要約で、ニュアンスの違いや画像の世界観を比較していきます。
桃太郎の要約
桃太郎のお話は皆さんも一度は読んだことがあると思いますが、要約すると下記の4シーンで構成されています。
桃から生まれた桃太郎がおじいさんとおばあさんの元ですくすく育つ。
強くたくましく育った桃太郎は鬼ヶ島へ鬼退治をしに出発。
犬、猿、キジにきび団子を渡して仲間にする。
鬼を倒して宝物を手に入れる。
この4つの要約文をそれぞれGoogle翻訳APIで英訳したものを入力文として画像を生成し、4コマの画像要約をしていきます。
1. DALL・E 2
「DALL・E2」はOpenAIが公開した画像生成モデルです。現時点ではクローズドベータ版として公開されており、2022年5月上旬以降に順番待ちリストに登録した人から順次利用可能になっています。一部有料化し、生成した画像の商用利用も可能だそうです。
何はともあれまずは桃太郎の要約文から画像を生成してみました。
1シーン目

(訳:桃から生まれた桃太郎がおじいさんとおばあさんの元ですくすく育ちました。)」
やはり桃から人間が生まれるなんて発想がないのか、完全に桃に全振りした画像が出力されました。
2シーン目

お!これはちょっと桃太郎の世界観が表現されていると言っても過言ではないのではないでしょうか。次に期待です。
3シーン目

ここで突然桃太郎がおじいさんになってしまいました。さあ後がなくなった桃太郎、無事に宝を手に入れられるのでしょうか。
4シーン目

(訳:桃太郎は鬼を倒して宝物を手に入れました。)」
う〜〜ん、鬼と桃太郎が融合してしまいました。やはり前後の文脈を加味しないと一連の物語を表すのは難しそうです。ただ全体的にアニメ調の画像が多く、物語の絵要約としては親和性が高いかも…?
2. Midjourney
お次は誰でも簡単に、たった1分でプロのような芸術的な絵が描けると話題の「Midjourney」。Discordというチャットサービスのアカウント登録をすれば、誰でも簡単に利用することができます。
1シーン目

(訳:桃から生まれた桃太郎がおじいさんとおばあさんの元ですくすく育ちました。)」
こちらもやはり桃要素強めですね。ただ昔話っぽいテイストになっているのが面白いです。
2シーン目

こ、これはかっこいい!!!強くなって鬼ヶ島へ行く主人公感満載の画像です。
3シーン目

犬、猿、キジが絶妙なバランスで融合された新しい生き物も生み出してしまいましたが、右上の画像なんかはそれっぽいものが生成されていますね!
4シーン目

(訳:桃太郎は鬼を倒して宝物を手に入れました。)」
鬼と鬼の住むお城のような情景、そして強そうな背中の桃太郎がきちんと表現されているように思えます。Midjourneyは幻想的な建物や抽象的な絵画が得意なようですね。
3. Stable Diffusion
最後の「Stable Diffusion」はイギリスのスタートアップ企業Stabilityがオープンソース化し、公開したモデルです。画像生成AIを利用したWebサービス「DreamStudio」のβ版を同時にリリースしました。こちらもMidjourneyと同様に、アカウントを登録すれば誰でも利用することができます。
https://github.com/CompVis/stable-diffusion
1シーン目

(訳:桃から生まれた桃太郎がおじいさんとおばあさんの元ですくすく育ちました。)」
こちらも昔話のテイストに近いですね。やはり桃から生まれてくることは困難なようですが…。
2シーン目

今までの中で一番桃太郎のお話に合った画像が生成されているかもしれません!さて次は鬼門の3シーン目、どうでしょうか。
3シーン目

んんん急な桃太郎実写化…!やはり3シーン目は新しい生物生み出しがちなようです。
4シーン目

(訳:桃太郎は鬼を倒して宝物を手に入れました。)」
ラスト4シーン目、鬼退治してる感はありますね。固有名詞よりも一般名詞の方がよりテキストの内容に沿った画像が生成されるかと思いきや、桃太郎は学習データにあったのかきちんと入れた方がそれっぽい画像が生成されることが分かりました。
まとめ
それぞれ1シーンごとに1枚の画像を選んで4コマ抽出した結果が下記の通りです。

上の画像だけ見ても、なんとなく桃太郎のお話を連想することもできるのではないでしょうか。正直ここまでリッチな画像を生成することができるとは驚きました。DALL・E2はアニメチックなポップなテイストであったのに対してMidjourneyは幻想的で統一感があったり、Stable Diffusionは昔話のようなテイストが上手く表現できていたりとそれぞれ異なる特徴も見られて面白かったです。また、画風や絵の内容などを指定して生成することもできるようなので、お試しの際には活用してみてはいかがでしょうか。
今回は日本語のテキストを英訳して入力しましたが、日本語の複雑な表現も拾うことができるモデルができたらもっと表現の幅が広がるかもしれませんね。
(メディア研究開発センター・新美茜)