92号:境界値分析: 後編

≡ はじめに
「ASTERセミナー標準テキスト」の100ページについてです。
前回は、境界値分析の基本と「無効同値パーティションはどこまで……」という話について書きました。今回は「3ポイント境界値分析」を中心に書きたいと思います。
「3ポイント境界値分析」については、(私が)理解不十分なところもあり、辰巳さんや湯本さんに教えてもらっているのですが、まだ分からないこともあるので、今回は俺流の「3ポイント境界値分析」の話になります。
ということで、疑問に感じるところがありましたら以下に出てくるJorgensenの本を併せてお読みください。
≡ 3ポイント境界値分析
前回説明した境界値分析は、「2ポイント境界値分析」とも呼びます。2ポイントがあれば3ポイントもあるだろう? ということで今回は、「3ポイント境界値分析」について説明します。
「3ポイント境界値分析」については、Jorgensenの『Software Testing: A Craftsman’s Approach』という書籍に詳しく載っています。私はずっと、これから書く方法とJorgensenの方法が同じものと信じていたのですが、微妙に違うようです(JSTQB FLシラバスに書いてある境界値分析はJorgensen流だそうです)。
ということで以下に書く方法については取りあえず「秋山がいつもしている3ポイント境界値分析」の説明ということにさせてください。(誰かが考案した方法であることが分かりましたら追記します)
Jorgensenの本は買った記憶があるので持っているはずなのですが、部屋のどこかに埋もれているか貸し出し中でみつかりません。 ><。
プロなんだから「もう一冊買ったらいいのに」と思うのですが、“Edition 5”が出てからかなあ。
なお、「3ポイント境界値分析」の話はちょっとややこしいので、以下の説明については、自分でノートに図を描きながら読み進めないと迷子になるかもしれません。
そうならないように丁寧に書きますが、下手に丁寧に書くと今度は文字数が増えるので理解しづらくなりますし、、、悩ましいです。
結論から言うと、「3ポイント境界値分析」は、同値分割したときの同値パーティションの最小値と最大値が信用できないときに使います。信用できない例として、まず、東海道新幹線のぞみ号停車駅の話を再掲します。
「東海道新幹線の“のぞみ号”は新横浜駅を出ると名古屋駅まで停車しません」
停車しない駅の同値パーティションを考えてみます。“こだま”が止まって“のぞみ”が止まらない駅は{小田原、熱海、三島、新富士、静岡、掛川、浜松、豊橋、三河安城}です。したがって境界値分析を行い求めた境界値(テストする値)は「小田原と三河安城」です。
※ 東北地方にお住まいの方は、「東北新幹線の“はやぶさ”は、大宮駅を出ると仙台駅まで停車しません」と読み替えると分かり易いかと思います。
こちらについて、新横浜~名古屋まで、“こだま”が止まって“のぞみ”が止まらない駅の境界値(最初の値と最後の値)を「小田原と名古屋」に【間違えた】とします。(「名古屋まで」は「金曜日まで」と同じ記述なので含むと勘違いしたとの想定です。
勘違いした想定のときの「止まらない駅の同値パーティション」の最初の値と最後の値は“小田原”と“名古屋”ですから、「最小値ー1、最小値、最大値、最大値+1」を「最初の値の1つ前、最初の値、最後の値、最後の値の1つ後」と読み替えれば、「2ポイント境界値分析」でテストすべき境界値は、「新横浜、小田原、名古屋、岐阜羽島」と導くこととなります。
岐阜羽島は東京から見て名古屋の次に“こだま”が止まる駅です。
★ これでは本当の最後の値である「三河安城」がテストされません ★
止まらない駅に対して、本来テストすべき境界値は「新横浜(最初の値の1つ前)、小田原(最初の値)、三河安城(最後の値)、名古屋(最後の値の1つ後)」です。
さてここで、「仕様に現れた値とその前後の3ポイントを取る」という方針で考え直してみます。仕様は、
「東海道新幹線の“のぞみ号”は新横浜駅を出ると名古屋駅まで停車しません」
でした。仕様に現れている駅は、「新横浜駅」と「名古屋駅」です。
「仕様に現れた値とその前後の3ポイントを取る」という方針で駅を選んでみましょう。
すると、仕様に現れた新横浜と名古屋の前後を含め「品川、新横浜、小田原」と「三河安城、名古屋、岐阜羽島」の6ポイントとなります。
この6つの駅には、「2ポイント境界値分析」で正しい境界値である、テストすべき「新横浜、小田原、三河安城、名古屋」の4つが全て含まれていることに注意してください。
テスト回数は4回から6回と1.5倍に増えますが、境界値のテスト漏れを無くすという点では優れています。
期待結果を正しく書けるかどうかはケースバイケースです。
別の例で説明します。
19歳以下と20歳未満は同じ意味(未成年)です。同値パーティションを書いて確認してみます。
19歳以下: 0, 1, 2, ,,, 17, 18, 19
20歳未満: 0, 1, 2, ,,, 17, 18, 19
全く同じです。
この有効同値パーティションの最大値に対して、2ポイント境界値分析をしたときに、うっかり、
19歳以下: -1, 0, 18, 19
20歳未満: -1, 0, 19, 20
としてしまうことがあります。
(“19, 20”の方が正解ですので、この例では「19歳以下」と仕様書に書かれていた時に、20歳のテスト漏れを起こしています)
さて、先ほどと同じ方法で、こちらの仕様に「3ポイント境界値分析」を適用してみます。3ポイント境界値分析は、「仕様に現れた値とその前後の3ポイントを取る」方法ですので、仕様に現れている「19歳」と「20歳」の前後をとれば良いので、
19歳以下: -1, 0, 1, 18, 19, 20
20歳未満: -1, 0, 1, 19, 20, 21
となります。
意味が分かりやすいように、議論になっている、「18, 19, 20, 21」のみを抜き出して、未成年の同値パーティションに含まれる値に「●」、含まれない値に「〇」を付けて書いてみます。
19歳以下: 18●, 19●, 20〇
20歳未満: 19●, 20〇, 21〇
パーティションについて、Beizerのように「同値パーティションを区切る仕切り版」という理解をすると、●と〇の間にはパーティションがあります。パーティション(間仕切り板)を「|」で表すと、縦棒は、必ず「●|〇」のように、黒丸と白丸の間に入ります。
ところで、仕様に書かれた値が黒丸であっても白丸であっても(←境界値を誤読したとしても)その前後の値は、片方が黒丸で、もう片方は白丸です。
ということは、仕様に書かれた値が黒丸のときには「●●|〇」、白丸のときには「●|〇〇」のどちらかのパターンしかあり得ません。
つまり、「3ポイント境界値分析」の結果選ばれた3値は、必ずパーティションの前後の2つの値(Beizer流の2ポイント境界値が正しく行なわれたときに選ばれる2つの値)を含みます。
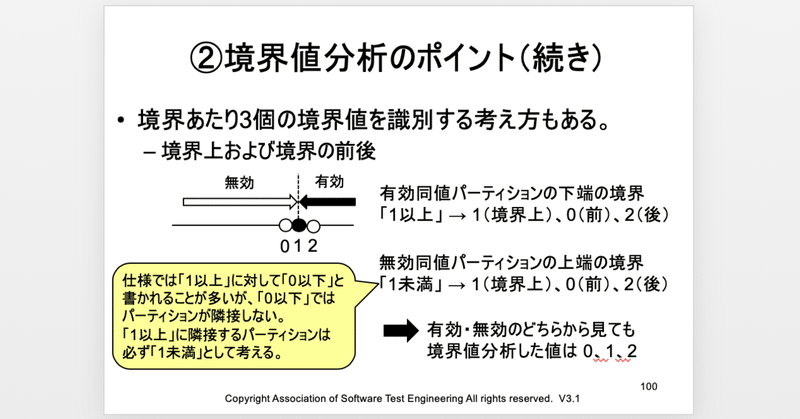
ずっと「仕様に現れた値」と書いてきましたが、バイザー本では「仕様に現れた値」を“Onポイント”と呼び、パーティションを挟んだ隣の同値パーティションの値を“Offポイント”と呼びます。ですから、「19歳以下」という仕様であれば、19歳がOnポイントで20歳がOffポイントですし、「20歳未満」という仕様であれば、20歳がOnポイントで19歳がOffポイントです。
ひとによっては、「着目している同値パーティションの最小値もしくは最大値をOnポイントと呼び、隣の同値パーティションのうち、着目している同値パーティションに最も近い値をOffポイントと呼んでいます。この呼び方の場合は、「19歳以下」という仕様でも、「20歳未満」という仕様でも19歳がOnポイントです。
したがって、Onポイント・Offポイントという言葉を使うときには、その定義を相手と共有しないと話がかみ合わなくなります。
ISTQB(Jorgensenの方法)では「境界値19と境界は同じもの」としています。そして、境界に対してその前後の3ポイントをテストする方法が「3ポイント境界値分析」と説明しています。
でも私は、境界値が何かについて確実に分かっているのなら「3ポイント境界値分析」は不要(使う意味無し)で「2ポイント境界値分析」で十分と思っています。
この辺の違いは、Beizerは「境界 = 値の間」としていて、Jorgensenは「境界 = 値」としているところに起因していると考えています。
そしてISTQB(や英国標準:BS 7925-2)ではJorgensenの方法を採用しているということです。私は、バイザー・ラブなので、2ポイント境界値分析派ですし、Onポイントは仕様で示された値派です。(笑)
なお、Beizerは「境界 = 値の間」としていますので、「3ポイント境界値分析」について私が知る限り言及していません。
私が書いてきた方法も3ポイントのテストをしたいのではなく、確実に2ポイントを選ぶことができないとき(最小値と最大値が曖昧なとき)に、その2ポイント(境界の前後の値)が必ず入っている3ポイント(仕様に書かれた値であるOnポイントと、その前後)をテストしたいという意図です。
≡ 色々な境界値
色々な境界値について説明します。
■ ループ境界
正式な呼び方は知りません。(“桁あふれ”が近いかもしれません)
自動車(やオートバイ等)のコンパネには、走行距離を表示するオドメーターがあります。オドメーターはその自動車(個体)における総走行距離を記録するもので、機械式のころは、99,999kmまで表示可能で10万キロになると00000に戻っていました。車検期間(1~3年間)に10万キロを超えて走る人は少ないですし、そんなに走ったら昔の車はガタがきて分かりますので、大きな問題にはならなかったのでしょう。
(大昔は、逆走することで、走行距離の値を減らすことができたようです。50年以上前の話です。今は逆走してもカウントアップします)
今はデジタルで999,999kmまで測定・表示されますので、走行距離を少なく見せて高く中古車を売りつける詐欺はできないと思います。(地球1周でも4万キロですし、自動車メーカーも情報改ざんへの対策を取っていますし)
余談の余談ですが、オドメーターそのものは、車が誕生するずっと前の紀元前の古代ギリシャにて、アルキメデスが発明したそうです。オドメーターの「オド」は、古代ギリシャ語で、「経路」「パス」「出入口」を表す言葉だったとか。
ここからが本題です。
整数型の変数をカウンターとして扱うことがあります。
例えば、符号付8ビット整数型(char)変数をカウンターとして使うことが出来ます。8ビットしかないため、扱える整数の値の範囲はー128~127です。
話を簡単にするため、こちらを使用した場合を考えてみます。
このときに、2進数表記で、0000 0000(0)から0111 1111(127)までは、順調にカウントアップします。
ところが、その次のカウントアップで、1000 0000(-128)となってしまいます。125, 126, 127, -128, -127, -126,,,です。127の次は一周回って、-128につながるイメージです。私はこれを「ループ境界」と呼んでいます。
これで問題が起こらない方が不思議です。実際に問題が起こり続けています。
2008年8月4日にNTTは、249日のルータ連続稼動で「ひかり電話」が発着信不能になる旨のバグ告知をしました(我が家にも葉書が届きました)。原因は書いてありませんでしたが計算すると、
248日×24h×60m×60s×100=2,142,720,000
2^31 = 2,147,483,648
249日×24h×60m×60s×100=2,151,360,000
なので、10msのカウンタが符号付32ビット整数型変数のループ境界を超えたのでしょう。
一般に249日もの長期間に渡ってテスト対象を連続稼働させるテストを実行することはないと思います。
私も「耐久性テスト」とか「連続運用テスト」といったテストタイプで、連続稼働させる(システムをリブートしないで使い続ける)テストをしてきましたが、最長でも1週間程度だったように思います。リソースの解放忘れといった欠陥の検出には1週間も連続稼働させれば十分でした。
別の方法として、テスト中に電源オフやリブートをできるだけしない機器を決めることもしましたが、この場合は、あまり約束は守られず、連続稼働は数日で終わっていることが多かったです。
テスト中は、不具合が改修された新しいバージョンを設置する必要がありますし、テスト対象として使える試作品はそんなに数が多くなかったからです。
また、カウンターとして利用する変数の型の(大きさの)検討が不足しているだけでなく、カンスト(和製英語なので外国ではCounter Stopと言わないと通じません)忘れのバグも多いものです。
カンストとは例えば、エアコンの設定温度を上げていって高温の温風が吹いていると思ったら設定温度の最大値で止まらずに冷風が吹き出したり、音量0(無音)の状況で音量を下げる[↓]ボタンを押したら大音量になったり、TVゲームで画面の右端にいたキャラクターが左端から現れたり、、、といったものです。似たような経験をみなさんされているのではないでしょうか。よく起こる問題なので、今テストしている商品やサービスで発生しても不思議ではありません。
さて、ループ境界のテストはどうしたら良いかというと、正攻法では難しいです。
まずは、どのようなカウンターを持っているかについて設計書に書き出してもらい、懸念点をレビューしましょう。
そして、テスト用にカウントの値を水増しするツール(先の例なら248日時点のカウント値に強制セットするツール)を用意してもらってテストします。
これをやってみると、レビューでほとんどの問題は指摘されました。また、どうしてもカウンターが必要な場合は案外少ないことが分かりました。(例えば、前後関係を調べることが目的なら日時データで代用できますし、ファイル名が重ならないようにしたいならユニークなファイル名を作成する方法が用意されています)
■ 正規表現
入力したデータのチェックに正規表現を使う場合があります。
正規表現とは、例えば、「a*」が「"", "a", "aa", "aaa",,,」、つまり、「aの0回以上の繰り返し」を表現するといったもので検索のときに使うと超便利なやつです。
正規表現は全てのソフトウェア技術者が知っている方が良い基礎知識なので、『詳説 正規表現』を読むといいです。
この本は、528ページもあって長いけど、ソフトウェア業界にいるのなら極める価値はありますし、極めなくても(正規表現に代わる技術が今後生まれるとも思えないので)一生の財産になると思います。
話は戻りますが、例えば、名前の「ふりがな」が「ひらがな」となっていることをチェックするために、正規表現の[あ-ん]を使ってしまう人がいます。
これについて、テストをしても、ひらがなは受け付け、それ以外は拒否するため[合格]としてしまいがちです。ところが、[あ-ん]の指定では、小さな「ぁ」が漏れています。「ぁ」を名前に持つ人は少ないのでリリース後もなかなか問題に気付き難いものです。
先日お亡くなりになったヴァン・ヘイレン氏のように、小さな「ぁ」を持つ名前は、外国人にはいないこともないのですが、日本だと、、、「東京アヴァンギャルド」しか思いつきませんでした。
ひらがなではなく、カタカナを指定しようとして[ア-ン]とすると、[ァヴヵヶ]が漏れます。ヴァン・ヘイレン氏なら2文字も引っかかりますね。
(ちなみに半角カタカナは[ヲ-ン]と指定すると全ての半角カタカナを指定したことになります)
このようなバグは、「それを知っていたかどうか」だけの問題です。したがって、変わったバグのニュース等を覚えておくしかないと思います。(ノウハウ・データーベースに格納して皆で共有するといった対策もありますが、エディタや統合開発環境(IDE)などに組み込まれていない限り、ノウハウをIT技術で活用することは難しい……ほとんど上手くいかない……んですよね)
変わったニュースといえば、例えば、「“ん”で始まる名前を登録不可にしていたらアフリカ人が困った」というニュースを思い出します。
このニュースの人ではありませんが、「ンドカ・ボニフェイス」という名前のナイジェリア出身のサッカー選手がいますね。ナイジェリアではそれほど珍しい名前ではないそうです。「ん」といえば、松本穂香さん、、、みんな観よう。
他にも「国際航空券には、『姓は2文字以上の入力が必須』かつ、『パスポート名と航空券名が一致しないと搭乗不可』という条件があるのに、日本には「井」さんや、「伊」さんがいるので、彼らは毎回困っている」だの、、、こちらは文字長の境界値問題ですが。
「井」さんや、「伊」さんは、国際航空券は、「II」の2文字表記になります。ただ、パスポートは「I」1文字です。よって、搭乗時に止められるそうです。(事情を説明して通してもらう)
豆知識ですが、日本以外では姓が1文字の名前を持つ国はないそうです。韓国の李(リ)さんを思い出しますが、「Lee」もしくは「Li」と表記しますのでこの問題には該当しません。
知識の有無によって、テストの良し悪しが決まるのは、技法推しの私としては悔しい話ですが、これも一つのドメイン知識なのでしかたありません。
■ 日付の仕様
問題を3問出します。
≪問題1≫
1月10日にチェックインして1泊するホテル予約を、1月7日にキャンセルする場合、キャンセル規定表の何日前のキャンセルのところを参照すればよいですか?
≪問題2≫
民事訴訟法285条は「控訴は,判決書・・・の送達を受けた日から2週間の不変期間内に提起しなければならない。」と規定し、控訴期間を定めています。3月1日に判決書の送達を受けた場合、何月何日から何月何日までの間が提起可能な2週間にあたりますか?
≪問題3≫
3月1日から起算して10日間とは、何月何日から何月何日までですか?
空行
空行
空行
≪回答≫
問題1: 3日前です。
問題2: 3月2日から15日までです。
問題3: 3月1日から10日までです。
いかがでしたか? 全問正解の方も少しは迷ったのではないでしょうか。
日付や時間はとにかく仕様が複雑です。
ですからテストケースや期待結果は慎重に作る必要があります。
※ まずは、「○月×日から起算して」とあったら「○月×日から」(○月×日を含む)と覚えてください。逆に言うと「起算して」と書いていない場合はその日を含まないことが多いです。
≡ 終わりに
今回は、「3ポイント境界値分析」の話がメインでした。正直、仕様があいまいなら、仕様書のレビュー、あるいは、テスト分析中に、最小値と最大値についてトコトン調べる方が無駄がなくて良いと思います。
逆にいえば、テスト設計技法で頑張る話ではないと思います。(本来はそうであっても、しなくてはならないときだってあります)
したがって、「3ポイント境界値分析」の話は、テスト技法の講師をされるような人しか興味のない話かもしれません。
さて、まとめになりますが、境界値分析は技法そのものは簡単でも仕様についての詳細な(厳密な)知識を必要とするので、そこが難しいと感じる部分だと思います。
特に、「期待結果」を正しく書けなかったり、正しく書けたとしても、(テストの期待結果と実行結果が異なったときに)実際の動作の方が正しいのだろうとバグ票の起票を躊躇しがちです。知見者に聞いて一つひとつ覚えていくしかありません。
それから、「(期待結果を)正しく書けていない」ことに気が付かない可能性にも(謙虚になって)注意してください。
「期待結果を正しくかけたか?」という質問は、「XXを紛失した」と言っている人に「どこで無くしたの?」と聞くようなものです。
だからこそ、「3ポイント境界値分析」のように、実装の問題の検出だけなら2ポイントで十分なところを3ポイントテストすることで仕様化のミスを補っているのだと思います。
最後に、境界値分析のことをBVAと呼ぶ人がいます。流行ってほしくないので最後に書いているのですが、「Boundary(境界)のValue(値)をAnalysis(分析)する」の略です。BVAと呼ぶ人は同値分割法をEP(Equivalence Partitioning)と呼びます。セットですね。
次回はデシジョンテーブルテストについて書きたいと思います。
この記事が気に入ったらサポートをしてみませんか?