
【AI analytics連載】Amazon SageMakerによる機械学習実験管理

こんにちは、AIX Labの川角です。
AIX LabではSMSやHR領域をはじめとしたAI関連の新規開発や先行研究の調査などを行っています。
今回は、AWSが提供するAmazon SageMakerを用いた機械学習の実験管理について紹介したいと思います。
Amazon SageMakerとは
Amazon SameMakerは機械学習のモデル開発から利用までのワークフローをサポートするAWSのサービスです。
SageMakerには機械学習のサンプルスクリプトや組み込みアルゴリズムも豊富に用意されているので、データサイエンスの深い知識がなくても機械学習を実践したいエンジニアやビジネスマンでも利用できるものになります。
SageMaker Experimentsとは
SageMakerの実験管理機能としてSageMaker Experimentsが利用できます。機械学習実験とモデルバージョンの整理、追跡、比較、評価からモデルのデプロイまで一元管理できる大変便利なツールです。
機械学習の実験管理ツールとしてはMLFlowやWeights & Biasesも有名ですが、モデル開発と実験管理をSageMakerのJupyter Notebookでオールインワンで行えるのは魅力ですね。
さらにはSageMaker Autopilotを使うことで、ローコードでモデルのチューニングを自動で行う機能も備えています。
動かしてみる
早速動かしてみましょう。SageMaker入門者でもわかるようにステップバイステップで記載します。
まずSageMaker studioでnotebookを開いて、実験管理に必要なSagemaker experimentsをインストールします。
import sys
!{sys.executable} -m pip install -qU awscli boto3 "sagemaker>=1.71.0,<2.0.0"
!{sys.executable} -m pip install sagemaker-experiments次に、必要なライブラリをimportしましょう。
import boto3
import botocore
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from time import strftime, gmtime
import sagemaker
from sagemaker import get_execution_role
from sagemaker.predictor import csv_serializer
from sagemaker.debugger import rule_configs, Rule, DebuggerHookConfig
from sagemaker.model_monitor import DataCaptureConfig, DatasetFormat, DefaultModelMonitor
from sagemaker.s3 import S3Uploader, S3Downloader
from smexperiments.experiment import Experiment
from smexperiments.trial import Trial
from smexperiments.trial_component import TrialComponent
from smexperiments.tracker import Tracker今回サンプルデータとしては、有名なボストンの住宅価格データセットを使います。サクッとscikit-learn.datasetsから取り出しましょう。
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
features = pd.DataFrame(housing.data, columns=housing.feature_names)
target = pd.DataFrame(housing.target, columns=['target'])
data = target.join(features)データはこんな感じです。targetが予測したい住宅価格、それ以外は年収帯、築年数、部屋数、緯度経度などの特徴です。

ここでポイントですが、一番右側のカラムをターゲット(目的変数)にしましょう。
SageMakerの組み込みアルゴリズム(今回はxgboostを使います)を利用する際には、Xとyを分ける必要はありません。一番右側をターゲットデータとして識別するのでこのように整形します。
データセットが用意できたのでtrain, validation, testに分割し保存します。
from sklearn.model_selection import train_test_split
train_valid, test = train_test_split(data)
train, valid = train_test_split(train_valid)
train.to_csv('train.csv', index=False, header=False)
valid.to_csv('valid.csv', index=False, header=False)
test.to_csv('test.csv', index=False, header=False)次に、データセットをS3にアップしましょう。S3にバケットを作ってそこにtrain, validation, testを分けて格納します。
s3url = S3Uploader.upload("train.csv", "s3://<bucket_name>/train")
print(s3url)
s3url = S3Uploader.upload("valid.csv", "s3://<bucket_name>/validation")
print(s3url)
s3url = S3Uploader.upload("test.csv", "s3://<bucket_name>/test")
print(s3url)S3にデータがアップできたら、sagemaker.s3_input または、sagemaker.TrainingInputで読み込みましょう。どちらを使うかはSDKのバージョンに依存する様です。下記はsagemaker.s3_inputの例です。
s3_input_train = sagemaker.s3_input(s3_data="s3://<bucket_name>/train", content_type="csv")
s3_input_validation = sagemaker.s3_input(s3_data="s3://<bucket_name>/validation", content_type="csv")
s3_input_test = sagemaker.s3_input(s3_data="s3://<bucket_name>/test", content_type="csv")これでSageMakerの組み込みアルゴリズムが読めるsagemaker.inputsオブジェクトが作成できました。
それでは、ここから実験です。まず実験セッションを作成しましょう。
sess = sagemaker.session.Session()
create_date = strftime("%Y-%m-%d-%H-%M-%S", gmtime())
housing_experiment = Experiment.create(experiment_name="housing-xgboost-{}".format(strftime("%Y-%m-%d-%H-%M-%S", gmtime())),
description="xgboost for housing",
sagemaker_boto_client=boto3.client("sagemaker"),
)
print(housing_experiment)Experiment(sagemaker_boto_client=<botocore.client.SageMaker object at 0x7f8b28aa1d50>, experiment_name='housing-xgboost-<日時>', description='xgboost for housing',......
が出力されます。ここではトライアルの名前に日時が入るようにしています。
つづいて、SageMakerの組み込みアルゴリズムのイメージを獲得します。ここではテーブルデータに頑強な精度を発揮するxgboostを使います。
from sagemaker.amazon.amazon_estimator import get_image_uri
docker_image_name = get_image_uri(boto3.Session().region_name, "xgboost", repo_version="1.0-1")実験のトライアル(trial)を作成し、実験開始です。hyperparamsで任意のパラメータを入力し、Estimatorにパラメータを渡します。.fitする際には、上で作成したsagemaker.inputオブジェクトを渡せば学習が始まります。
trial = Trial.create(
trial_name="algorithm-mode-trial-{}".format(strftime("%Y-%m-%d-%H-%M-%S", gmtime())),
experiment_name=housing_experiment.experiment_name,
sagemaker_boto_client=boto3.client("sagemaker"),
)
hyperparams = {
"max_depth": 3,
"eta": 0.2,
"gamma": 4,
"objective": "reg:squarederror",
"num_round": 25,
}
xgb = sagemaker.estimator.Estimator(image_name=docker_image_name,
role = sagemaker.get_execution_role(),
hyperparameters=hyperparams,
train_instance_count=1,
train_instance_type="ml.m5.large",
output_path="s3://<bucket_name>/output",
base_job_name="xgboost-housing",
sagemaker_session=sess)
xgb.fit(
{"train": s3_input_train, "validation": s3_input_validation},
experiment_config={
"ExperimentName": housing_experiment.experiment_name,
"TrialName": trial.trial_name,
"TrialComponentDisplayName": "Training",
},
)結果を確認しましょう。SageMaker resources→Experiments and trials→experiments選択→trial選択→metricsタブ。

trainとvalidセットの評価指標(RMSE)が確認できますね。
ではこれを、パラメーターを変えて実験してみましょう。試しにxgboostのmax_depthを複数試してモデルの複雑さを制御してみましょう。
max_depths = [2, 3, 4, 5]
for depth in max_depths:
hyperparams["max_depth"] = depth
trial = Trial.create(
trial_name="algorithm-mode-trial-{}-depth-{}".format(
strftime("%Y-%m-%d-%H-%M-%S", gmtime()), depth
),
experiment_name=housing_experiment.experiment_name,
sagemaker_boto_client=boto3.client("sagemaker"),
)
t_xgb = sagemaker.estimator.Estimator(
image_name=docker_image_name,
role = sagemaker.get_execution_role(),
hyperparameters=hyperparams,
train_instance_count=1,
train_instance_type="ml.m5.large",
output_path="s3://<bucket_name>/output",
base_job_name="xgboost-housing",
sagemaker_session=sess,
)
t_xgb.fit(
{"train": s3_input_train, "validation": s3_input_validation},
wait=False,
experiment_config={
"ExperimentName": housing_experiment.experiment_name,
"TrialName": trial.trial_name,
"TrialComponentDisplayName": "Training",
},
)こちらも結果をみてみましょう。複数の結果をリスト表示するには、trialを複数選択→右クリック→Open in trial component list で表示できます。
こんな感じでモデル、評価指標、パラメータの一覧が表示できます。

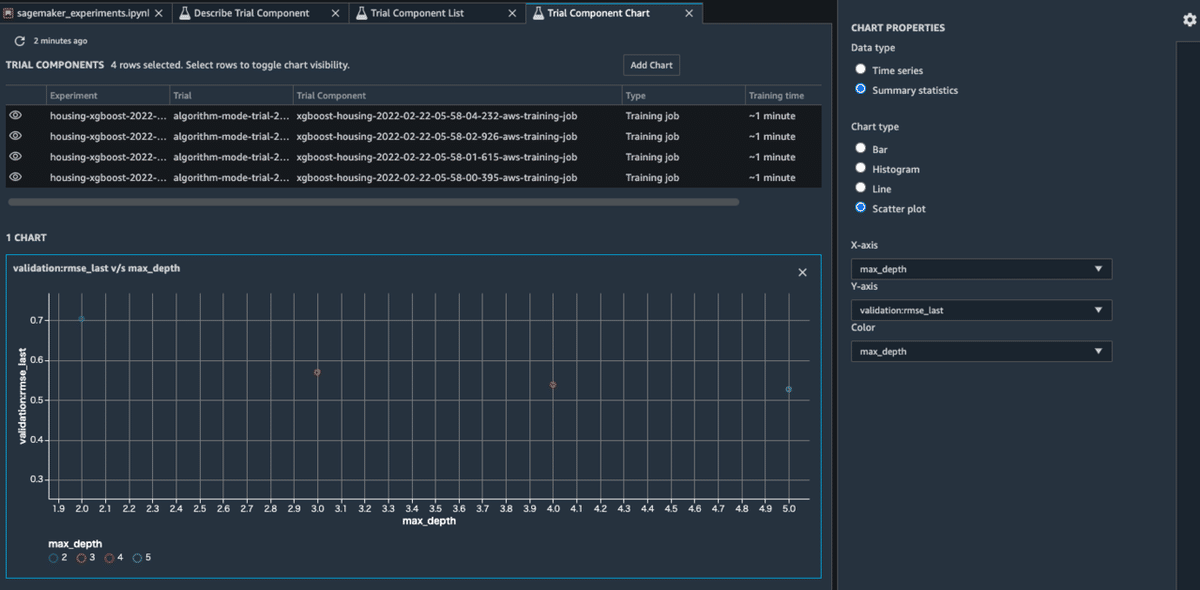
表示するカラムは右上の設定ボタン(歯車)から選択できます。この例では、max_depthが大きくなるとともに、モデルが複雑になり損失が小さくなることがわかりますね。
簡単なMetricsの可視化も可能です。上のリストで複数選択→Add chartを押すとチャートが開きます。左側のCHART PROPETIESをした図のよう設定すると、パラメーターに対する評価指標の変化が可視化できます。
最後にモデルをデプロイして予測してみましょう。使用するモデルの名前とインスタンスを設定して、xgb.deployを実行します。インスタンス立ち上げには数分かかります。
xgb_predictor = xgb.deploy(model_name='algorithm-mode-trial-2022-02-22-05-58-03-depth-5',
initial_instance_count=1,
instance_type="ml.m5.large"
)予測結果を得るために下記の関数を使います。
from sagemaker.predictor import csv_serializer
xgb_predictor.content_type = 'text/csv'
xgb_predictor.serializer = csv_serializer
xgb_predictor.deserializer = None
def predict(data, rows=500):
split_array = np.array_split(data, int(data.shape[0] / float(rows) + 1))
predictions = ''
for array in split_array:
predictions = ','.join([predictions, xgb_predictor.predict(array).decode('utf-8')])
return np.fromstring(predictions[1:], sep=',')テストセットを使って予測してみましょう。
y_pred = predict(test.iloc[:,1:].values)
print(y_pred)[2.01921916 1.70753121 0.98497015 ... 2.2977643 2.26125836 0.63274741]
これで、住宅価格の予測結果を得ることができました!!
予測器を使い終わったら不要なコストがかからないように、必ずエンドポイントを削除しておきましょう。
xgb_predictor.delete_endpoint()使ってみてどうだったか
SageMakerは最初は慣れが必要ですが、Jupyter Notebookでモデル開発〜モデル管理が一元管理できるのは大きなメリットかと思います。
SageMakerに用意されているサンプルノートブックや組み込みアルゴリズム、自動でパラメータチューニングするAutopilotなど上手く使えば、
機械学習モデルの開発スピードも向上すると思います。
おわりに
AI CROSSでは、次々に登場する新しい技術やフレームワークも活用しながら、Smart Work, Smart Lifeの実現に向けて、日々SaaSサービスの開発・改善に取り組んでいます。
これからもAI CROSSの活動や、利用・注目している技術の解説などを発信していこうと思います。
それでは今日はこのへんで。
この記事が気に入ったらサポートをしてみませんか?