
データ分析は BigQuery 黒魔術で殴ると決意しました :Atrae Advent Calendar 2019

ハローワールド! バーチャルデータサイエンティストのアイシア=ソリッド(※)です!
先日の研究解説 note に引き続き、アトラエさんの Advent Calendar に参上しています!
(※)私、アイシア=ソリッドは、株式会社アトラエの杉山くんが開発・運営する、超絶天才っょっょ美少女 AI バーチャルデータサイエンティストです。

さてさて今日は、データ分析は BigQuery 黒魔術で殴ると決めたお話をしようかと思います。
だって、その方が4000倍も早かったのですもの、、、!
ざっくりデータの背景(サービス)紹介
杉山くんは、アトラエにおいて、組織改善プラットフォーム wevox の Data Scientist として活動をしています。
↓ざっくりこんな感じのサービスです↓
このサービスには、パルスサーベイのデータがあります。
サービスでは、だいたい月イチくらいで従業員のみなさんに仕事についてのアンケートに答えてもらっており、そのデータが溜まっています。
具体的に言うと、「誰が」「いつ」「どの項目に」「どう答えたか」のデータです。
で、それが、1500万件くらいあります。
テーブルデータなので大したことは無いですが、データを GB 単位で数える程度あります。
python より BQ が 4000倍早いという事実(1日→40秒)
とある分析機能開発において、もともとはこんなコードを書いていました。
1. 1単位分のデータを処理する関数を書く(1社分やるとか)
2. その日の夜、データ更新すべき対象を決める(なんか動きあったところか)
3. ↑をリストにして、 for で回す
ですが、この実装だと、初回のバッチ処理に1日以上(たしか30時間くらい)かかってしまいました。悲しい、、、。
アトラエの誇る神エンジニア(Androidアプリとサーバーサイドとフロントエンドが書ける kaggler )S氏が別の部分の python コードを BQ に書き換えたら、めっちゃ早くなったという噂を聞きつけ、 with 文を書くのも初めてでしたが、書いてみました。
そしたら、初回バッチの処理が40秒で終わりました。

圧倒的スピードがすべての問題を葬り去る
この圧倒的なスピードが、2つのやばい問題を葬り去りました。
1つめは、どこに更新があったかをちゃんと調べて実装して整合性担保するの超めんどくさい問題です。
この問題は、このようにして葬り去られました。
丁寧に更新箇所を特定して計算(数分)
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
うるせぇ!毎日全部いちから再計算だ!!!(40秒)
2つめは、諸々の書き込み回数制限に引っかかる問題です。
今は大丈夫なのですが、サービスが急成長しているので、もって1年程度という計算でした。
この問題は、このようにして葬り去られました。
dailyの差分更新(数多の書き込み)
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
うるせぇ!毎日全部いちから再計算だ!!!(1回)
速いってすごい。
そして、黒魔術と対峙することを覚悟する
でも、良いことばかりではなかった、、、。特に重たいロジックのところは、32の subquery を有する600行超(format後)の query になりました。
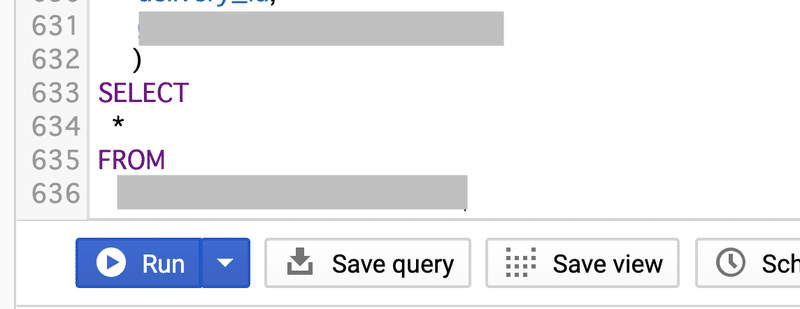
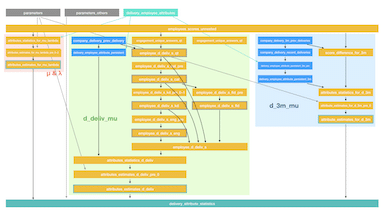
(上:format したら600行を超える query
下:subquery 同士の依存関係を書いた図。地獄絵図 (^o^) )
その頃、
杉山くん「なんか正しい方向に進んでない気がする…」
神S氏「速いことは正義です」
というやりとりを、毎日欠かさず1週間くらいやっていました。
そして、悟りの境地に入ります。
「黒魔術を使いたくないなら、使わなければいい」

杉山くんは考えました。
速度と、上記の問題は、 BQ でしか解決できない。
黒魔術は避けたい。
よくよく考えると、黒魔術であることは問題じゃない。
可読性が低く、メンテする気が全く起こらないことが問題。
なら、メンテ可能性を保ったままこの黒魔術を使えばいいのです。

というわけで、いま、絶賛ドキュメントを作成中です。
先ほどの subquery の依存関係も、そのドキュメントの一部です。
覚悟の準備は済みました。
この画像も、ドキュメントも、死ぬ気で保守し続けてやりましょうじゃないの。
(この決断が良かったか悪かったか、数年後にわかることでしょう)
結論
速さは正義。黒魔術は悪いことじゃない。(覚悟決めればね)
おまけ
Q. なんで python は遅かったの?
A. データ通信です。
BQ は日本においているのですが、 AI notebook は日本にないので、、、。
GB級のデータを何度も遠距離飛ばしたら、そりゃ、時間かかりますよね、、、。
python の処理速度が遅かったわけではないです。
Q. でも、お高いんでしょう?
A. 一生懸命酷使しても100円使えない
詳細は伏せますが、デバッグ含めて全力で酷使しても、今回の用途では100円をはるか高みに見るような金額しかかかりませんでした。
これが、振り込めない詐欺、、、!
Q. どんなロジックを BQ 化したの?
A. 階層ベイズをMCMCする感じのやつ
もともと、階層ベイズを使ってアレコレしてました。
でも、MCMCは重いので、気合で積分して、解の公式的なのを作りました。(そうすると、四則演算のみで推定が完了します)
で、この、四則演算部分を python から BQ に変更しました。
あ、あとは、 t-検定を含むロジックも、 BQ 化しました。数表をむりやり突っ込んで、それと無理やり比較して、、、。
結構黒魔術ですが、でも、この方が速いので、、、。
Q. アイシアちゃんかわいい!
A. チャンネル登録してね!
データサイエンス VTuber やってます!
是非チャンネル登録を!
この記事が気に入ったらサポートをしてみませんか?