
ビジネスにおけるデータの見方と使い方

キャデイでコストアルゴリズムの作成をしている阿部です。
”コストアルゴリズム”というとあたかもTech組織に属していそうですが、Biz組織として位置づけられています(コストアルゴリズムをプロダクトに取り込む組織は別でTech組織に存在する)。
キャディの業務紹介スライドで【新製品開発・コストアルゴリズム】チームのMUST要件にも書かせていただいていますが、ここで言う「データ分析スキル」とはどのようなものでしょうか?社内向けの「データ分析(基礎編)」資料を改編してそのさわりだけお伝えできればと思います。
*コストアルゴリズムそのものや業務内容について具体的に記すのは難しいので、是非ご興味持っていただけましたらDMいただけると幸いです!!

キャディはマッチングプラットフォームでも商社でもなく、ファブレスメーカーです。
— 阿部和大@CADDi (@KazuhiroAbe1) August 20, 2020
これを支えるのはWholeProductとしての仕組み化の強さ。
コストアルゴリズムのチームも積極採用です!
bizからtechへの橋渡しを一緒に推進しましょう!
DMお待ちしてます! https://t.co/sryiV9wDjv
# これはなに
- データ分析における基本的かつ汎用的な考え方を示したもの
- 統計学や実験研究の分野であれば大学の最初に習うような内容
「データ分析」と聞くと、excel/python/SQL/SPSS/Rなどツールの使い方やt-test(ABテスト)/分散分析/因子分析/主成分分析/重回帰分析など分析手法の話に進みがちですが、そこは「データ処理」の領域です。ビジネスにおけるデータ分析の一番の価値は事業インパクトを出すための行動を定義することであり、分析者の腕の見せ所はどの視点でデータを見れば説得力を持ってその行動を定義できるのかを発掘する点にあると個人的には考えています。
そのためビジネスサイドの行動を決めるためのデータ分析であれば、本記事に書いてある程度の観点を習得していれば、後はやりながら分析手法やツールの使い方、データを見る視点はブラシュアップされていき、データ分析者としての戦闘力が自ずと向上していくものだと考えています。
*勿論ツールや統計的なアプローチを使いこなせることも武器となりますし、実際SQLは社内で多くのビジネスサイドの人間が書いてます。
# ビジネスにおけるデータ分析の目的
定量的にデータ傾向の差分を見出し、その意味を解釈して次のアクションを生むためのもの
よって
分析の結果、アクションが変わらないような粒度でデータを見る意味はない
よくある失敗として「あれもこれも見たい!とあらゆるカットでデータを分けた結果、データの膨大な羅列が生まれ、示唆出しに困る」というのがあります。これは「データはあるが活用できていない状態」です。
データ分析の意義はやるべきこと、やらなくてよいこと、そしてその根拠を示すことでもあると思います。戦略とは限られたリソースの最適配分なので、データ分析はそのリソースをどこにフォーカスすべきかを導くための武器であり、最小努力で最大成果を生むための武器と言えます。
# データ分析の外観
1. データ分析アプローチ
分析のアプローチとして大きく2つあります。
1-1. 仮説検証アプローチ
これはrawdataを見る前に「どういう条件で収集したデータに関して、なんのデータが、どうであれば、○○と言えるのか」仮説の定義ができる類の分析です。
仮説構築時点からABテスト(t検定)、分散分析で検証することを見越して、その後データ取得を走らせる方がデータの欠損やノイズは少なく分析はしやすくなります。(というかそもそもあるデータで何か示唆を出すというのは非常に難易度が高く、データクレンジングにも時間を要するの、仮説検証アプローチを取れる領域なら予め分析を見越してデータ取得をすることを強くオススメします。)
例えば、webマーケの改善アプローチはイメージがしやすいでしょう。
考え方は前職でマーケ/事業企画をしていた頃に書いた記事がありますのでよろしければご参考ください。
1-2. 探索的分析アプローチ
これはrawdataを色々な見方で見ていかないと明確な仮説が立てづらい分析です。
「〇〇によって結果に差が生じていそうだが、複合的な要因かもしれないし、ハッキリとは言えない」といったケースです。
具体的には
- 新規事業立ち上げ期におけるテストマーケ(リサーチや定性的なヒアリングを元に仮説構築し、1-1. 仮説検証アプローチを取ることもある)
- 顧客開拓戦略決め
- SaaSビジネスのCSのサポート戦略決めや顧客価値の特定
etc
ちなみに弊社のコストアルゴリズムのブラシュアップにもこのアプローチを取ります。
2. プロセス一覧
上記で紹介した仮説検証アプローチと探索的分析アプローチの2つのアプローチにおける一連のデータ分析プロセスは下記のイメージです。
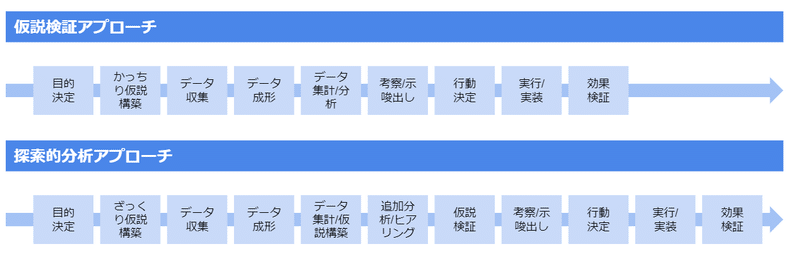
共通するのは、分析の目的を定義し、仮説を出し、データを分析可能な状態に成形、そして仮説に従いデータの羅列に意味を見出していき、データが示す意味について解像度を上げ、何らかの解釈をして(示唆を出し)、取るべき行動を導き出す、という流れです。
次のセクションで具体的な注意点を工程ごとにピックアップしていきます。
3. 各プロセスにおいて特に注意すべき観点
上記で示したプロセスの中で特筆すべき観点がある工程について抜粋してお伝えします。
3-A. 目的決定
この工程では、そもそもなぜ分析をするのか、前提条件や背景情報の整理をすることで要求強度や方向性の認識を揃えます。
例えば、私の所属するコストアルゴリズムのチームにおける[コストアルゴリズムの磨き込み]の文脈で言うと、biz本部のOKRが何で、そこに対してコストアルゴリズムのチームはどのような貢献をしたいのか、その上でなぜその領域の改訂が必要なのか?というように、自身の行動が社内、さらにはその先にいらっしゃるお客様やパートナー会社様への価値提供に繋がっているのか、そのインパクトはどれほどかという観点の整理します。
この工程はおざなりにしがちですが、一連のデータ分析を航海とするとこの工程は方位磁針のようなものです。自分たちがどこに向かっているのか、迷った時に常に立ち返るものです。言語化を怠るとデータの海に溺れて死にます。
3-B. 仮説構築
先述の目的決定と被りますが、目的より進みたい方向性の具体度が上がったものです。データは数値の羅列の状態から意味のまとまりを見出すためにデータの見る視点を決めなければなりません。
仮説検証アプローチの場合は「どういう条件で収集したデータに関して、なんのデータが、どうであれば、○○と言えるのか」言語化できます。一方で探索的アプローチの場合はかっちりは決まらないので、ざっくり決めておきます。しかしその場合データの波に飲み込まれてしまう恐れがあるので(時間をかけてデータを見たのに何も示唆が得られない、など)必ず分析の目的は忘れないよう目に入る位置に書いておくことをオススメします。
3-C. データ収集と成形
一連のデータ分析力がここまで記載した内容に対して「ふむふむ、そうだよねー」と思える以上であるという前提に立つと、OPSの変化が激しいスタートアップ、ベンチャー、新規事業の立ち上げ期において一番の難所はこのデータ収集と成形の工程だと個人的には思います。
現状のデータ基盤の整備状況を捉えた上で構築した仮説を検証するためには「どのようなデータをどこから収集したらよいのか」を設計する力が求められますし、データ基盤やデータフローへの理解が最低限ないと狭義のデータ分析工程(データ集計や処理)まで辿り着けません。
webマーケなどオンラインに完結する世界観、成功モデルが確立されOPSも固定化されている世界観においてはノイズデータや欠損データの存在はそこまで意識せず、データ処理工程に入ることができることも多いでしょう。
しかしbizOPSフローが型化されていない状況下においてはノイズデータの除外、データ欠損の補完等の作業が不可欠です。ここに関しては”データ分析者”になるためにまず”データ取得の仕組み構築者”としての仕事もせねばなりません。
*データがどのようなOPSケースにおいても漏れなくミスなく入るに越したことはないが(そんなことはほぼあり得ない!!)、そうでなくとも分析フェーズで排除できるように、分析に使えないデータかそうでないのかの判定は最低限できる必要があり、そのためにフラグを設けたりします。
各データカラムの定義やbizOPSのどの業務工程でどのデータがどこに入るのかというデータフロー、そしてデータ構造の理解がないと本来見たいデータではないものを抽出し、分析していた、ということになると大惨事です。分析業務において一番避けたいのは出戻り工数が生じることなのでここは丁寧に進めたい工程です。
*組織としては各データカラムの定義をし、分析用のマスターデータの整備/メンテナンスをできる人がいると望ましいと思います。bizサイドで色々な人がデータ構造やカラムをいじれてしまうような運用状況ではデータ分析に耐えうるデータ基盤構築は無理なので、プロダクトオーナーは必要でしょう。
3-D. データ集計/分析
この工程が一般的にイメージされがちな所謂”データ分析”だと思います。データ分析に対する勘違いを解くためにこの工程以外の重要性を説いてきましたが、勿論この工程も分析者としての腕の見せ所が詰まっています。
ここではあらゆる種類のデータの見方に適用できるよう基本的かつ汎用的な視点を紹介します。分析業務を普段されている方にとっては釈迦に説法な内容となります。
データ分析において重要な概念として、独立変数(説明変数)・従属変数(目的変数)があります。
従属変数は結果指標であり、独立変数はその結果を生み出す原因となっている可能性のある指標です。
例えば営業組織で「受注率を高めるために何をしたらよいのか?」という問いがあり、データ分析を試みたとします。
そこで[受注率]を従属変数とし、受注に寄与する要因を考えます(仮説構築工程)。お客様の会社規模/担当者のITリテラシー/地域/お客様の事業領域/商談時の感触/BANTに定義される所要の状態像等、お客様要因の変数もあるかもしれません。一方で社内営業担当者の力量/社内のOPS状況等社内要因の変数もあるかもしれませんし、市況や競合サービスの登場など、市場環境要因の変数もあるかもしれません。上記であげたような[受注率]という従属変数に影響を与えている可能性のある変数のことを独立変数と言います。
ここで思い出してほしいのですが、ビジネスにおけるデータ分析の目的は何でしょうか?
定量的にデータ傾向の差分を見出し、その意味を解釈して次のアクションを生むためのもの
です。分析した上で、では我々はどうしたらよいのかを示すことに意義があります。データ分析において結果を説明する方程式を明らかにし、市況や競合といった自身でコントロールしにくい要因の存在も理解した上で、目的とする変数をいかに理想に近づけていくか、そのためにコントロールできる変数は何かを特定し、そこの改善行動をしていく必要があります。
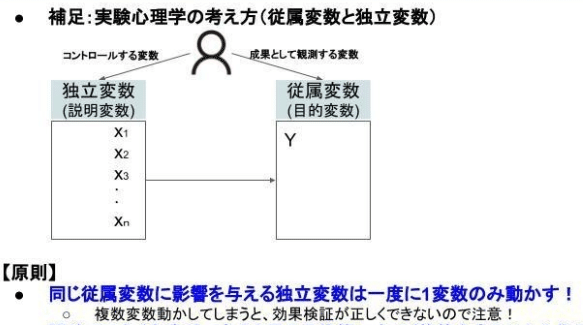
「従属変数を説明する変数は何か、各独立変数はそれぞれどの程度従属変数を説明しているのか」これを明らかにするために重要なデータの見方の原則があります。
それは
ある従属変数に影響を与える独立変数は一度に一変数のみ動かす
ということです。
そうでないと結果に対してどの変数が寄与したのかわからなくなるからです。
新規事業あるあるですが、早く成果が欲しいが故に思いつく施策をあれもこれも同時にやってしまうことがあります。これは成果が上がった場合も上がらなかった場合も「何がよかったのか、だめだったのか」の効果検証ができないのでNGです。
例えばマーケ施策でCVRの向上のためにサイトの写真も文言もボタンの配置も一度に変えてしまう、といったことがあり得ます。
3-E. 考察/示唆出し
分析/仮説検証によって得られた結果(事実)に対して解釈(意味づけ)をする工程です。
【空・雨・傘】のフレームで言うと、雨が分析結果、傘が考察/示唆出しにあたります。
この工程での注意点は、「事実と解釈、感想と事実、目的と手段、願望と示唆、期待と結果、相関と因果は似て非なるものであり、分けて論じる!」という点です。結果や事実は誰が見ても同じことが言える状態のことを言いますが、解釈/感想は人によって異なります。
4. レポーティングで気を付けること
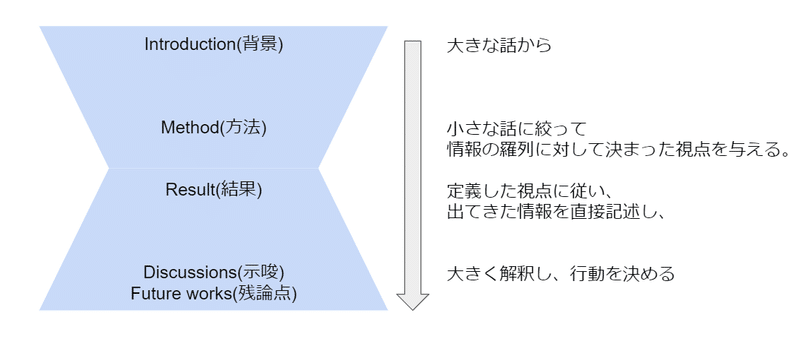
実験研究の論文の構成にIMRDという型がありますが、これはビジネス場面でのレポーティングでも有効なので念頭において書くとよいでしょう。
- Introduction(導入/背景):分析の目的や前提条件の整理をして認識を揃えた上で仮説を明記
- Method(方法):使用したデータや収集条件について
- Result(結果):データから読み取れる事実。誰が見ても同じことが言える情報のことを言う。個人的な解釈や感想、願望は混ぜない。
- Discussions(示唆):結果を踏まえて、どういう解釈をしたのか、その後のとるべき行動を示す
- Future works:今後追加で検証すること、残論点etc
大事なことは
- 当初の期待(仮説)に引っ張られた結果の報告や解釈はしない
- 数値の関係だけを見て相関と因果を混ぜて論じない
- 目的と手段を混ぜない。そもそも何のための分析でそのためにどの指標を見るのが意味があるのか、ぶれない。
という点です。特に相関と因果は混ぜて論じてしまうケースが多いので明確に言葉を分けて使いましょう。
また、結果は事実なので「誰が見ても同じことが言える状態」と先述しましたが、下記のように事実をどう意味のある情報としてレポーティングするかはデータリテラシーが如実に表れます。
最後にFuture worksについて触れます。ここで健全にディフェンスしておかないと意思決定者に変な突っ込まれ方をしてしまい、実は些末な観点であったり一旦進んでみてから追加検証すればいい観点だったとしてもやり直しになってしまうかもしれません。
それは非常にもったいないので(個人としても組織としても早く前に進めた可能性を機会損失してしまうので!)レポーティングの前に模擬プレゼンをしてみて(頭の中でも/箇条下記で骨子確認するでもよし)、「ここ突っ込まれそうだし、どうなっているか気になるよな」という観点は洗い出し、追加分析をかけるなり、残論点として「今回検証してないけど論点としてはわかってますよ」アピールをしておくなりしておきましょう。
# 最後にお知らせ!キャディは絶賛採用中です!
積極採用中ですので、少しでも興味を持たれたらご連絡くださいませ。DMウェルカムです!
その他のポジションであっても絶賛募集中です!
キャディはマッチングプラットフォームでも商社でもなく、ファブレスメーカーです。
— 阿部和大@CADDi (@KazuhiroAbe1) August 20, 2020
これを支えるのはWholeProductとしての仕組み化の強さ。
コストアルゴリズムのチームも積極採用です!
bizからtechへの橋渡しを一緒に推進しましょう!
DMお待ちしてます! https://t.co/sryiV9wDjv
# Appendix
・「データ分析はなんのためにやるのか?」という問いに対して「データ分析とは、意思決定の不確実性を減らすための試みである」と定義している下記の記事。非常に賛同しますし、データ分析のよくある誤解についても触れられている面白い記事です。
・本記事でも「一番の難所」として紹介したデータ収集と成形を楽にするためのインフラ構築≒データ基盤構築です。ここが整っていればデータ分析のプロフェッショナルが暴れ回る幅が広がります。
・データ分析入門書紹介(アカデミック編)
- 母校慶應義塾大学の心理学専攻では統計学入門として下記の著書を教科書として使っています。
- 下記も慶應義塾大学の心理学専攻での統計学の参考書として扱われています。
・データ分析入門書紹介(ビジネス編)
よろしければサポートよろしくお願いいたします!