
Pythonで機械学習『Iowa 家の販売価格予測 その3』002/100

先週前半、「Iowaの家価格販売予測チャレンジ」を始めてみたものの、わからないことだらけだった。それで、LightGBMやKFoldなどについて勉強してきたわけですが、少し理解がすすみましたので、再挑戦します。
まず初手として、特徴量をいじらずLightGBMに入れて、出力された値をベンチマークとし、そこから改善して行けたらと思います。Kaggleにも提出するぞ。
①初手LightGBM
まずは予測目的
与えられたデータから予測したいのはSalePrice。つまりobjectiveはregression。
予測値の対数とテストデータの対数の間のRMSE(Root-Mean-Squared-Error)で評価される。
次はデータ確認
学習データは、1460行で81列。
テストデータは1459行で80列。Salepriceがないので1列少ない。
学習データをテストデータの量が同じだな。クロスバリデーションのテストサイズを0.5にするか。0.2もして比較したい。
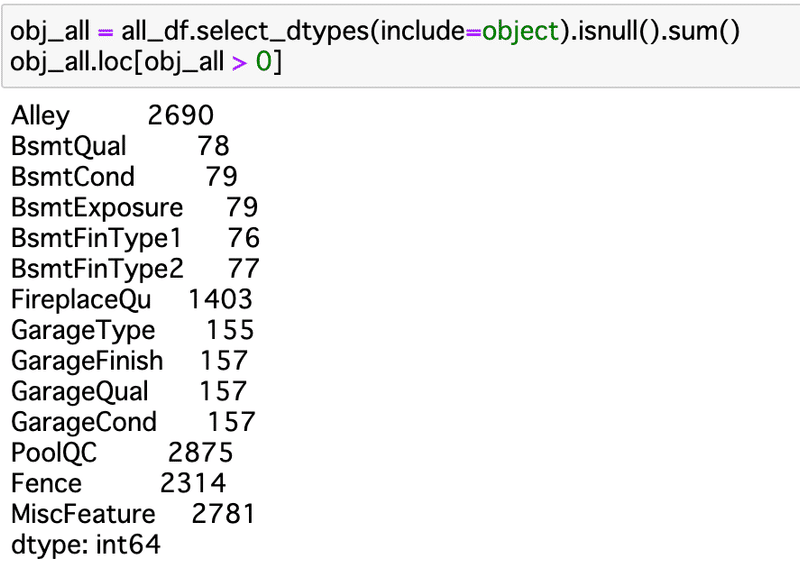
欠損値を確認。
LightGBMには欠損値のまま入れられるみたいなんだけど、カテゴリ変数をLabelEncoderに入れる時は欠損はNGなので、確認。
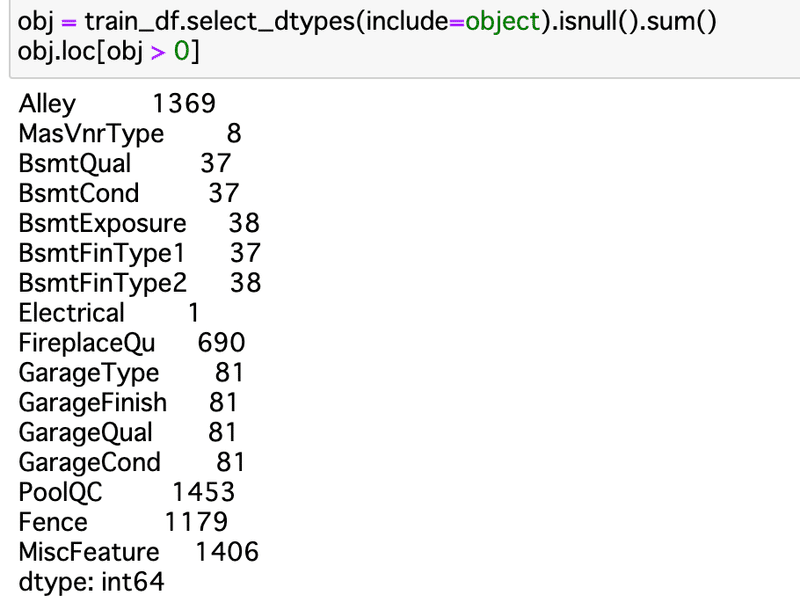
意味のある欠損と、謎という意味の欠損があると思われる。
確認したところ、ほぼほぼ欠損=NA、ない(たとえばプールがない)の意味だった。ので、あとで、'missing’にでも変換する。(NAとNaNは同じもののようだ。)
が、2点、気になるところがあった。
MasVnrType: Masonry veneer type
外壁にどんな石の装飾があるか、ってことだと思うんだけど、
Noneがある。NAと同じ意味だよね?と思ったらNoneもNaNもあるので、確証なし。8件が謎欠損。
Electrical:電気系統
ブレーカーとかヒューズボックスのこと。1件が謎欠損。
ここまできたところで、テストデータも同時にやるべきだったことに気づく。くそーやり直しかー。
ということでやり直した結果がこちら。
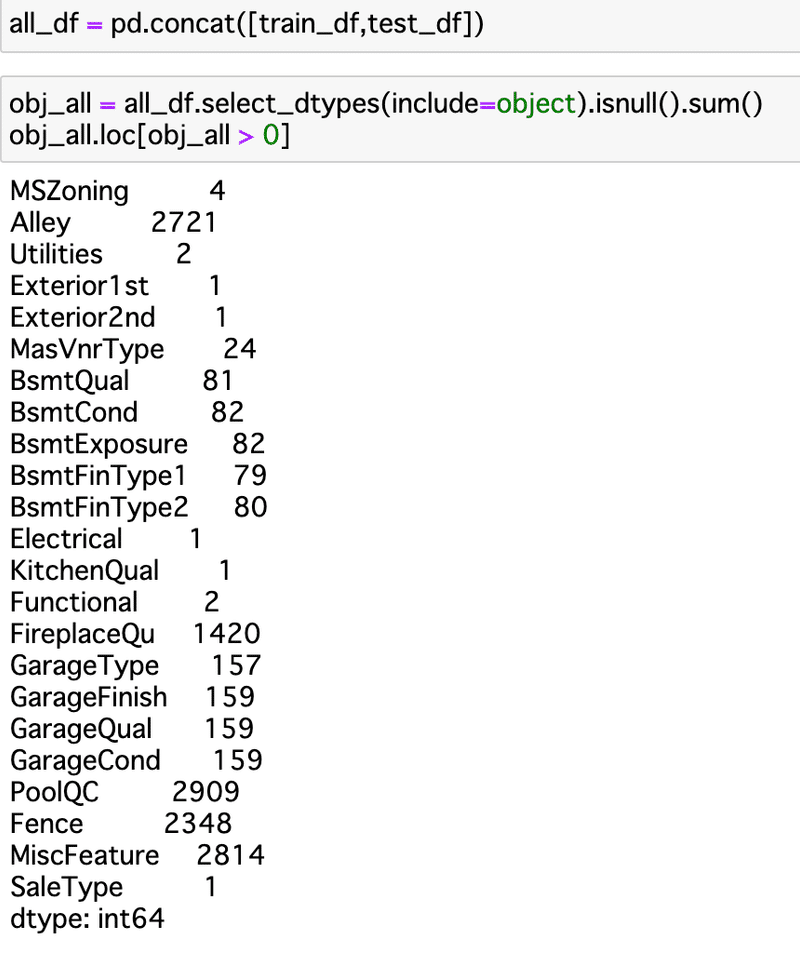
増えたし。
謎の欠損に、
MSZoning 4
Utilities 2
Exterior1st 1
Exterior2nd 1
MasVnrType 24
KitchenQual 1
Functional 2
SaleType 1
が追加。
しかも地下室とかガレージも微妙に数字ずれてるし。
データ数としては少ないので、謎の欠損がある行は削除する。
でもその前に、除外するデータが、SalePriceのヒストグラム上、どこにいるのかは一応みてみたい。
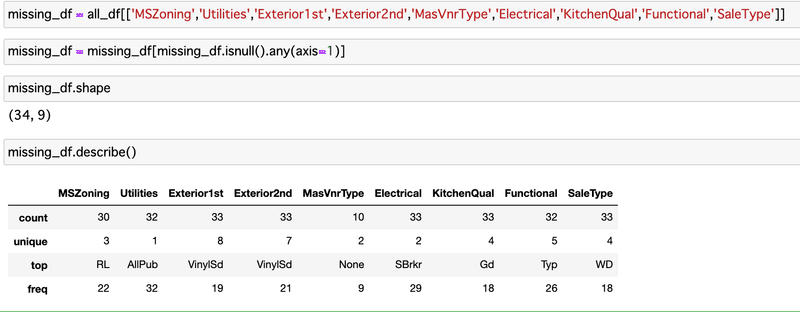
該当レコードは、34件。
NaNを含む行だけ抽出した。やり方がわからなくて、ものすごく苦労した・・・けど、めっちゃ良い方法を見つけた。
no_na = df.dropna()
only_na = df[~df.index.isin(no_na.index)]まず、欠損値ありデータを落としたデータフレームを作る。
そのインデックスを使う。
元データから、no_naデータフレームにあるインデックス番号がないものだけ抽出する。
という方法。助かったー、かっこいいー。こちらから。
SalePriceで見てみようかと思ったけどテストデータにはそのデータがそもそもない(そりゃそうだ・・・)ので、OverallCond: Rates the overall condition of the houseで見てみる。家の状態0〜10点評価。
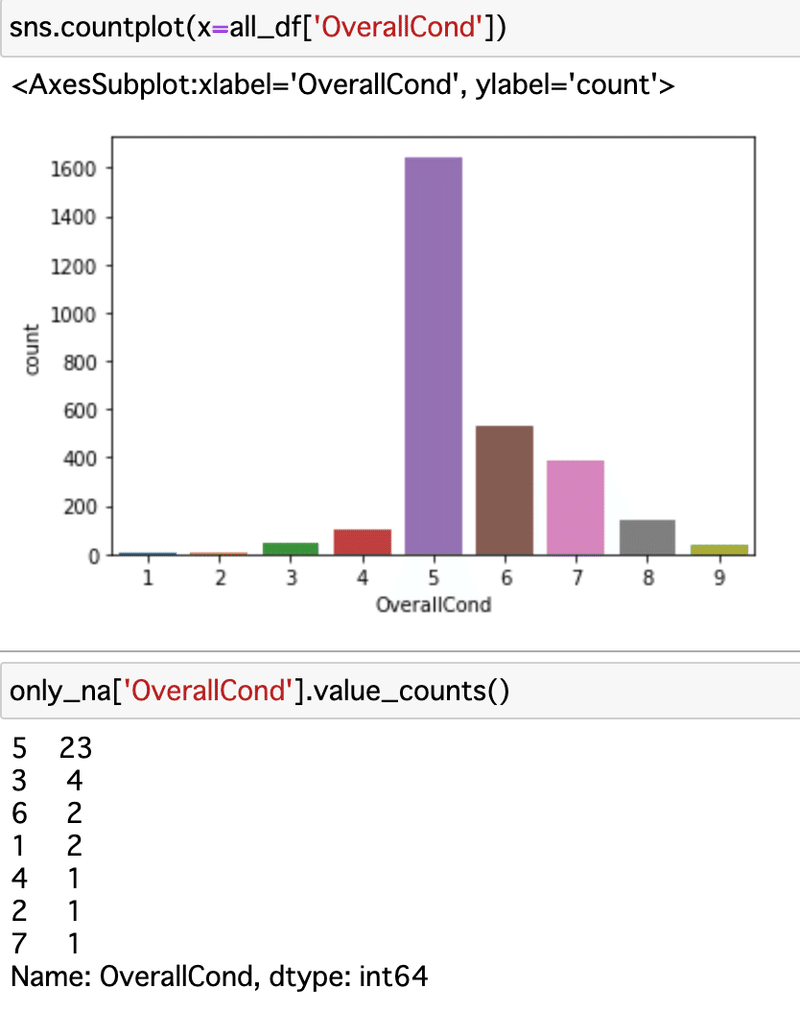
消そうとしているデータがほぼ5で一番多い。ので、大丈夫でしょう。
欠損のある34行を消します。
そして欠損値を確認。よし、ばっちり。
あれ、でもデータ消しちゃったら、予測の時に困るぞ。
うわーまだ消すタイミングじゃなかった。
間違えた。一度流れを整理しよう。
データを全て結合したあとに、
1、意味のある欠損と、謎の欠損を分ける。(インデックスを保存)
2、意味のある欠損をmissingに変換し、謎の欠損をnazoと変換する。
3、LabelEncoding(object型を数字に変換する)
4、学習データとテストデータとに戻す。
5、学習データの中の謎の欠損を、1のインデックスを参照しながら消すことを検討する。
だな。先走った。
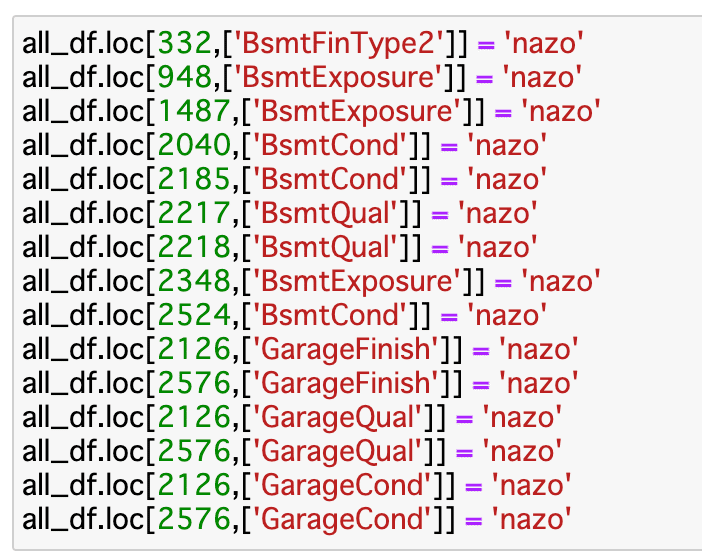
気を取り直してBsmtも一回見てみよう。欠損値の差が気になる。
Bsmt系で一個でも欠損があり、かつ、データ入っているレコードを抽出する。これらは、謎の欠損ですね。

最後はガレージ、こちら謎欠損。GarageTypeはDetchdなのに、他が欠損。

これで、1、意味のある欠損と、謎の欠損を分ける。(インデックスを保存)ができた。
次は、2。まず、謎欠損にnazoと代入し、最後にmissingをばーっと入れようかな。
絶対にもっといい書き方あるな。
できたけどね。object型データの欠損処理完了!

できた。嬉しい。
ようやくLabelEncodingだ。

とにかくモデル作ってみたいので、KFoldではなく、ホールドアウト法で一回モデリングしてみる。
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
train_x,valid_x,train_y,valid_y = train_test_split(X_train,Y_train,test_size=0.2,random_state=777)
import lightgbm as lgb
categories = all_df.columns[all_df.dtypes == 'category'].tolist()
lgb_train = lgb.Dataset(train_x,train_y)
lgb_eval = lgb.Dataset(valid_x,valid_y,reference = lgb_train)
lgb_params={
'objective':'regression',
'boosting':'gbdt',
'metric':'rmse',
'random_seed':777
}
model_lgb = lgb.train(
lgb_params,
lgb_train,
valid_sets=lgb_eval,
categorical_feature=categories,
num_boost_round=1000,
early_stopping_rounds=10,
verbose_eval=10)
y_pred = model_lgb.predict(valid_x,num_iteration=model_lgb.best_iteration)
rmse = np.sqrt(mean_squared_error(np.log(valid_y),np.log(y_pred)))結果は、

よし!
テストデータもPredictしてKaggleに提出するぞ!
結果は、、、
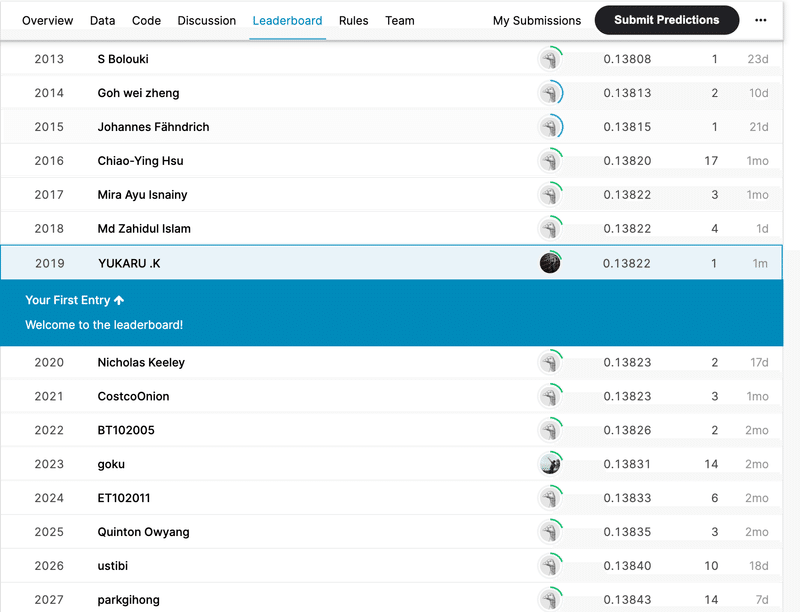
4963エントリ中、2019位。
真ん中よりちょい上。へー。
おっけー、じゃ次は1000位以内目指す!
この記事が気に入ったらサポートをしてみませんか?